monte carlo control
recap policy iteration

2 step = policy evalution -> policy improvment (greedy in this example) and repeat over and over until both converge
model free policy iteration using action value function

by considering action into account , we can have model free improvement
generalised policy iteration with action value function

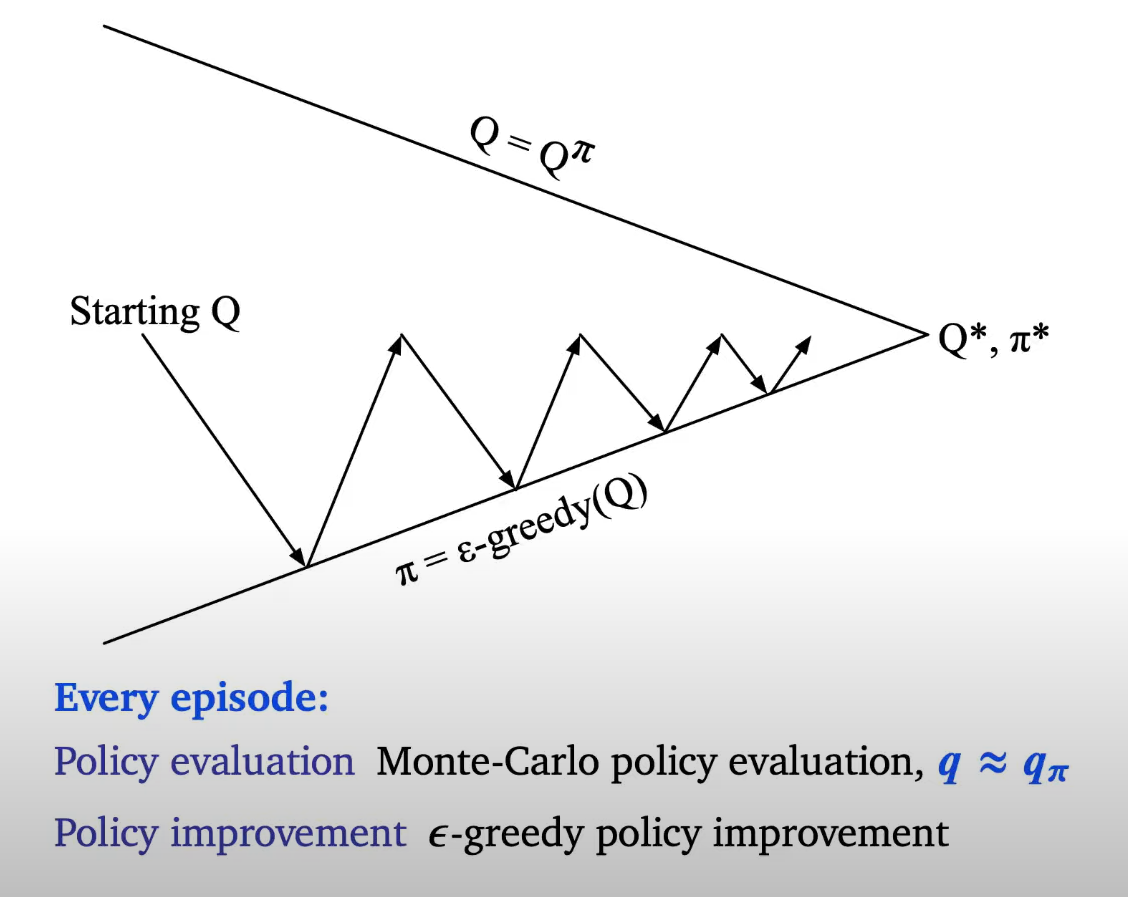
we are not evaluating whole policy , but instead , we are evaulating some policy and take greedy policy improvement
but does this converge? because we are not fully evaulating every policy
model free control

GLIE

eventually you will become full greedy
1st formula = the count for all state action pair (Nt(s,a)) should go infinity as time goes infinity
2nd formula = as time goes infinity it will be same as pure greedy algorithm
notice as steps go by we are decrementing epsilon
MC vs TD control (recap)

updating action value functions with sarsa

our target = immediate reward(Rt+1) + discounted next state action value
we compare current estimate q(St,At) to target and update with step size alpha
SARSA
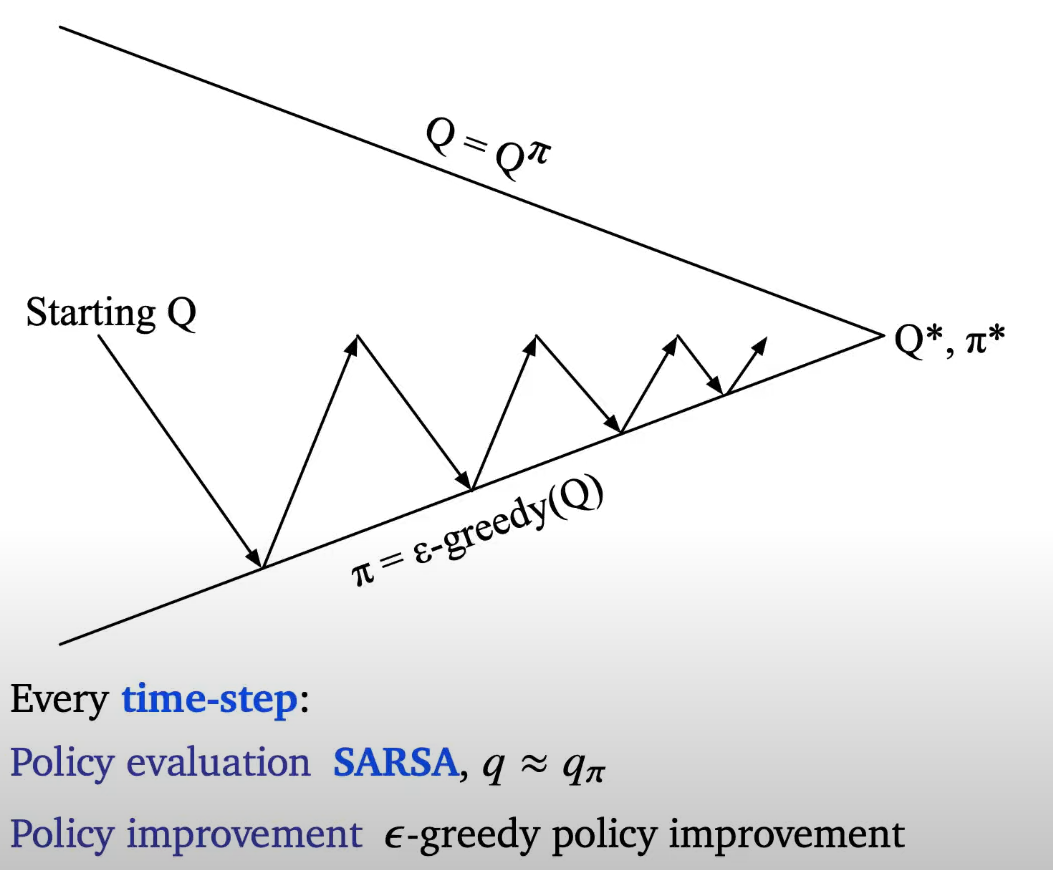
every evaluating step will be 1 time step and we will immediately do greedy

s = initial state of episode given by your environment , observation , agent state
Off-policy TD and Q-learning
DP


why there are 4DP algorithm but there are only 3 model free algorithm?
sarsa and q-learning difference is how we bootstrap
convience problem , value iteration on DP consider maximization outside of expectation so it is hard to pick a sample
On and Off policy learning

trying different policy
example of sarsa , q learning

if step size is 0.1 , then q(s ,down arrow) would update to 1.2 for Q learning case

why Sarsa is perfoming better than q learning?
sarsa = policy will later become quite stable due to reducing epsilon , but due to epsilon it will take safe path ,
if it takes optimal path there are high chance to fall in clif because sarsa takes random guess(probability epsilon).
q learning = by the 500 episode , it will learn optimal policy and walk optimal path
it has lower performance because exploring takes into account, policy is not greedy but random
Overestimation in Q-learning

we are using same value function to select and evaluate which is weird
we are picking an action that has high value and then we are saying "oh yeah i picked that because it has high value and now the value is high" that means we have upward bias
roulette example
always bet 1 dollar , we can pick color which gives double , or pick number which gives 36dollars , or stop
high nosiy environment = action values are going to be inaccurate in beginning

eventually Q-learning will converge to "Actual" but it is doing it extremely slow
problem is , as shown above , we are using same action value function for select and evaluate
Double Q learning

we only update one of q value if we update q value we use (1) , if we update q prime we use (2)
double Q learning also converges to the optimal policy under the same conditions as Q learning


3 because both q prime are zero. so we just average when evaluating with q ([4+2]/2) = 3
Off policy learning : Importance Sampling Corrections

x~d[f(x)] = want to sample f(x) under distribution d , but we don't have distribution d
d prime should not be zero = if you never actually do anything(sampling from d prime) you can expect to learn from it
by doing this we can scale up events that are rare under d prime but common under d and vice versa , d is what we care about

so same as above given policy "u" we can get unbiased estimate policy quantity for "pie" by sampling from last equation
importance of sampling for off policy monte carlo

last equation will give unbiased estimate of the value on under pi
can be noisy estimate == high varience , use TD
importance sampling for off policy TD updates


Expected SARSA

pie = target policy
unbiased compare to SARSA and lower varience , so more preferable than SARSA
'AI > RL (2021 DeepMind x UCL )' 카테고리의 다른 글
| Lecture 8: Planning & models (0) | 2021.12.25 |
|---|---|
| Lecture 7: Function Approximation (0) | 2021.12.19 |
| Lecture 5: Model-free Prediction (part 2) (0) | 2021.12.04 |
| Lecture 5: Model-free Prediction (part 1) (0) | 2021.12.04 |
| Lecture 4: Theoretical Fund. of Dynamic Programming Algorithms (0) | 2021.11.27 |