comparing MC vs TD

random walk example

using td

after 1 iteration only A is changing because when we go left once the value go down to zero, other case same as initial state(0 iteration , (0.5+0)/2)

alpha is learning rate , it is slow when small
MC has high varience requries lower learing rate, TD has lower varience than MC
Batch (updating) MC and TD

most likely model given this episode

TD exploits markov property = if your in state B it doesn't matter that you were state A before , you can just estimate value sperately
help in fully observable env
MC does not exploit markov property = whenever we are in state A it turns out that our second reward is zero this could be related.
help in parially observable env
muti step prediction

note that last reward at t+n is discounted only n-1 time. which is consistent with 1 step approach
but the value estimate is discounted n times

if we increase n -> variance go higher -> need more small step size
mixed mutip step returns


if lambda is 0.5 , 1step = 0.5 weighted, 2step = 0.25 weight and so on

Eligibility traces (HARD PART)
independence of temporal span



delta is 1 step TD error term , xt is gradient of your value function in non linear case (in linear case it will be one hot vector)
independent of the temporal span of the predictions
we don't need to store xt-1 , xt-2 and so one instead we just merge them together into "e" and we only have to store this 1 "e" vector

td(0) only 1 step , td(lambda) = update all of the states along the way
prove why it works

delta = 1step temporal difference error , Gt -v(St) = MC error

we had to wait until the end of episode because we have to wait for Gt to be completely defined
et = store feature vectors we have seen in previous state

because we doing full MC so discount here is appropriate for propgating information backwards
you shouldn't propagate information more than it used in these monte carlo returns which came in ealier state

independent of span (computational property)
can update its predictions during long episodes even though we started with MC
Eligibility Trace Intuition
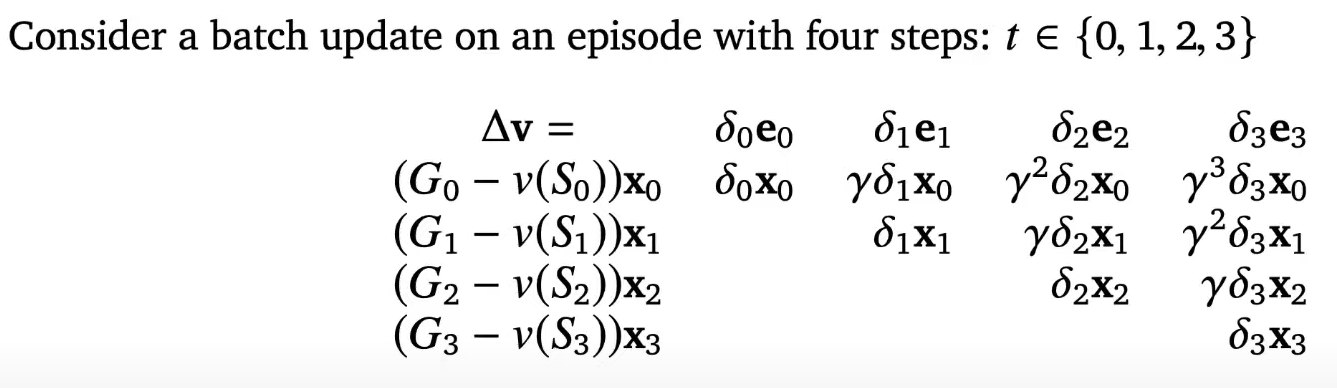
v should be w
notice all TD error are same in column so we are just adding "x" to e
mixing mutip step return + traces

offline = we store all of the weight updates we can add them together already but we don't actually change the weight yet
'AI > RL (2021 DeepMind x UCL )' 카테고리의 다른 글
| Lecture 7: Function Approximation (0) | 2021.12.19 |
|---|---|
| Lecture 6: Model-Free Control (0) | 2021.12.11 |
| Lecture 5: Model-free Prediction (part 1) (0) | 2021.12.04 |
| Lecture 4: Theoretical Fund. of Dynamic Programming Algorithms (0) | 2021.11.27 |
| Lecture 3: MDPs and Dynamic Programming (0) | 2021.11.20 |