Dynamic Programming
assume a model , solve model, no need to interact with the world at all
Model Free RL
no model, learn value function from experience
Model based RL

learn a model from experience
plan value functions using the learned model
model RL disadvantage
first learn a model , then constrcut a value function == 2 sources of approximation error
(in case of model free) learn value function directly == only one source of approximation error
pros of model RL
models can efficiently be learned by supervised learning method
Reason about model uncertainty since we modeled env we can do more explore little more smartly?
reduce the interaction in the real world ( interactino with env can be slow or expensive)
learning model

The above parameter (weight) called theta (something that looks like n)

not just linear model(expection model) we can use other thing like deep NN
stochastic model
we may not want to assume everything is linear
stochastic models (also known as generative models)

how we are going to parameterized model?

table lookup model

full distribution for transition dynamics and expectation model for the rewards

given exampel we used all of them (and doesn't consider explore) and made a model like right
Lienar expecation models


T, w is for parameter
planning for credit assignment
planning is the process of investing compute to improve values and policies without need to interact with the environment
intersted in planning algorithms that don't require priviledged access to a perfect specification of the environment
instead the planning algorithms we discuss today use learned models

learn from model's produced data and consider it as real environment interaction and use model free RL with them

the planning process may compute a suboptimal policy
combine model based and model free methods in a single algorithm == Dyna



d = apply direct q learning
e = update model , for instance in a tabular deterministic environment this is just storing the next state and the reward
f = mixing happens here , model + qlearning(model free)
Dyna-Q on a simple maze

discount factor exists so agent is trying to go S to G in shortest way possible
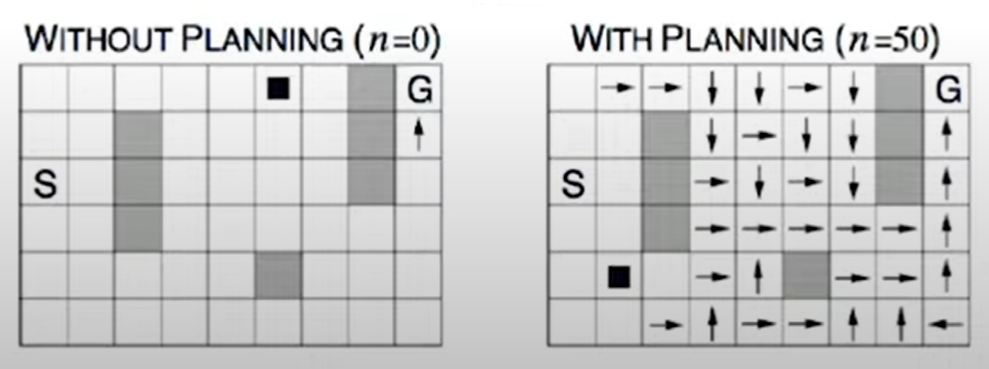
1st time step (episode)
n=0 == all the other states is zero except for one state close to Goal
n=50 == not just final state but actually updated many states ,
Dyna-Q with an inaccurate model

during learning the model became wrong due to change of environment
q+ == add exploration
AC == use actor-critc learning instead of Q - learning

only Q+ can realize fast there are shorter path because of exploration
Planning and Experience replay

but nowadays shar distinction between model based and model free is now less clear

parametric model


cannot be done with experience replay model but with parametric model
parametric vs experience replay

not saying which is best but we can choose the appropriate one depending on the problem
Monte Carlo Tree search

repeat until time allows, used in alpha go
note there are 2 simulation policies
a tree policy that improves during search
a rollout policy that is held fixed = often this may just be be picking randomly
Example

inside node left part is score , and right part is number of trial in simulation
star = state we selected
rollout policy = default policy
we updated our root to 1 because it is average of existing simulation

expand to one more node (star)
update star to 0 , update root to 1/2


advantage of MC tree search

search tree is a table lookup approach but only partially
'AI > RL (2021 DeepMind x UCL )' 카테고리의 다른 글
| Lecture 10: Approximate Dynamic Programming (0) | 2022.01.16 |
|---|---|
| Lecture 9: Policy-Gradient and Actor-Critic methods (0) | 2022.01.02 |
| Lecture 7: Function Approximation (0) | 2021.12.19 |
| Lecture 6: Model-Free Control (0) | 2021.12.11 |
| Lecture 5: Model-free Prediction (part 2) (0) | 2021.12.04 |