
before this lecture we assumed prior distribution to be simple gaussian , but now we want something more complicate so we can map more complex manifold.

it is hard to evaluate all the possible z, so in VAE we used encoder to find distribution z using q.
instead of passing the z through these 2 NN and then sampling from a guassian, we directly transform the latent variable by applying a single deterministic invertible function.
now it is trivial to figure out what was the z to produce that x, we just use invert function because it is unique.
from now on, the encoder will no longer perform representation learning. x and z dimensions are going to be same.

notice we only have 2 variable to modify this function (meaning it is simple)

just replacign variable is incorrect , need to use change of variables formula when dealing with pdf


since integral of pdf is cdf , we just use derivative
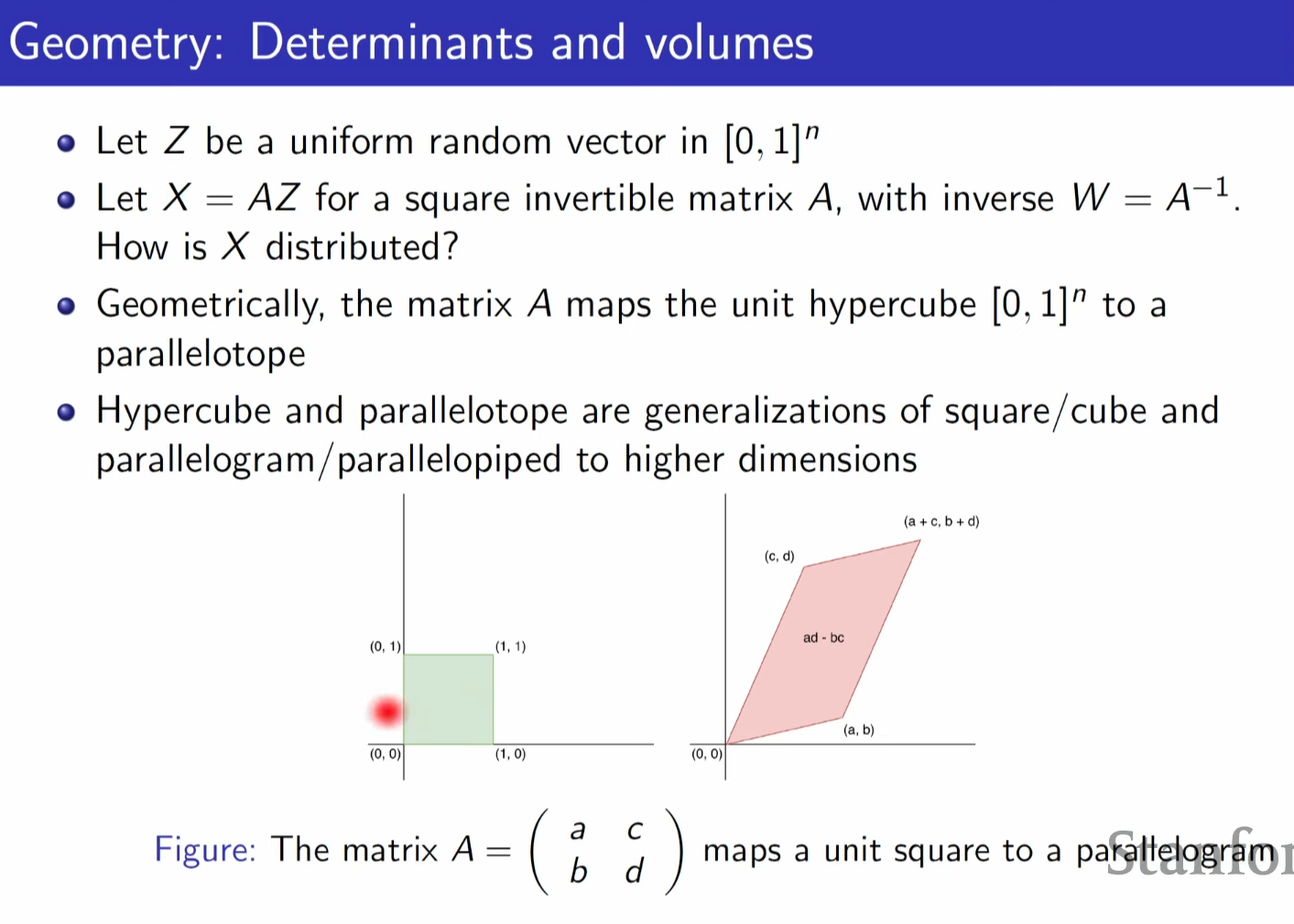

we divide by determinant of area of matrix to make p(x) to be probability , because area might get bigger due to linear transformation.
'AI > Stanford CS236: Deep Generative Models' 카테고리의 다른 글
| Lecture 6 - VAEs (0) | 2024.05.23 |
|---|---|
| Lecture 5 - VAEs (0) | 2024.05.21 |
| Lecture 4 - Maximum Likelihood Learning (0) | 2024.05.19 |
| Lecture 3 - Autoregressive Models (0) | 2024.05.18 |
| Lecture 2 - Background (0) | 2024.05.17 |