
using rnn with maksing to act like autoregressive model (looking back only , ordering conditional probabiltily)
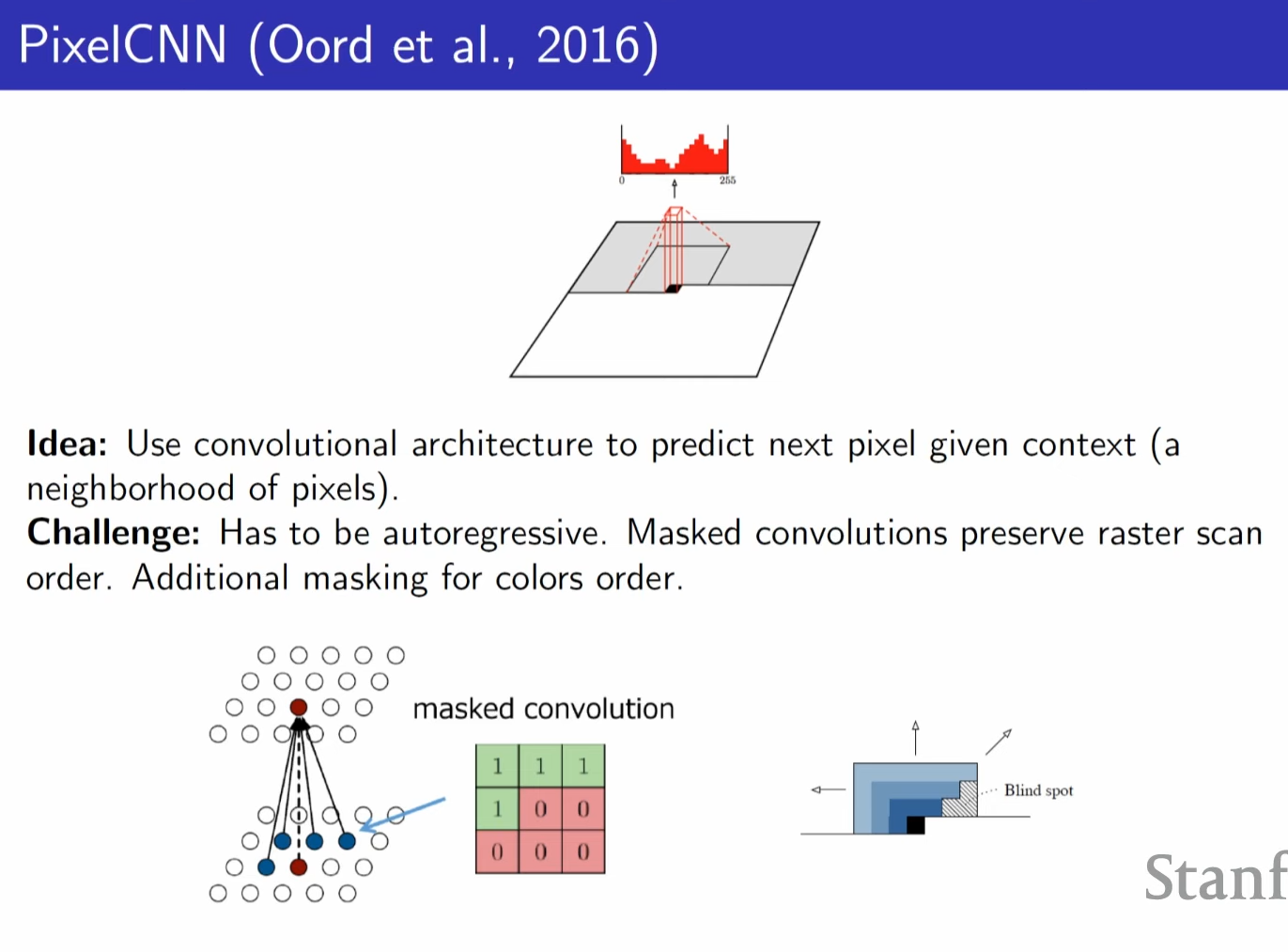
cnn with masked to be autoregressive, this masked convolution causes blind spot and need to be taken care of.
one way is to use multiple convolution with different masking

PixelDefend can detect adversarial examples
BPD(X) ~= − log pCNN(X)/(I × J × K × log 2) for an image of resolution I × J and K channels.
bits per dimension is about how many bits are required to encode single pixel.
in clean datset it is lower, but since other adversarial exmaple is added with some noise bits(metrics) it should have more bits, which cause more bits per dimension
Learning

even in simple 784 binary case, it is impossible to train with example
due to so many combination which leads to lack of comptuation resouce and time, we need approximation

1) example of Density estimation = anomaly detection, we would like to assign reasonable probabilities to every possible inputs , (full distribution) of course very hard problem
2) specific prediction task = has condition , which restrict combination , making model less parametjjer

similar to regression problem , since we want to label probabilities to all possible combination

KL divergence can meausre how much inefficent my model compression scheme is going to be.
problem is we don't have access to real data distribution.

we can develop equation further and notice first term is constant, all we need to is maximize second term.
which leads to expected log-likelihood

if we sample many, sample average will be close to actual data distribution average

given some training datas we can use chairule to develop equations to be product of conditional probability
but now we totally rely on optimziation algorithm to get MLE value, and thus no closed solution.


using monte carlo concept if there are too many data, we just pick some at do gradient descent == SGD
'AI > Stanford CS236: Deep Generative Models' 카테고리의 다른 글
| Lecture 7 - Normalizing Flows (0) | 2024.05.26 |
|---|---|
| Lecture 6 - VAEs (0) | 2024.05.23 |
| Lecture 5 - VAEs (0) | 2024.05.21 |
| Lecture 3 - Autoregressive Models (0) | 2024.05.18 |
| Lecture 2 - Background (0) | 2024.05.17 |