
위 3가지 조건을 만족하는 model distribution을 찾고 싶다.
in order to use chain rule you need to pick order, and there is no ground rule for this.
seperate probability distribution using chain rule.
first one is conditional probability table(CPT) because it is the very first pixel and doesn't rely on anything
from second pixel we use logisitic regression
autoregressive = trying to predict parts of each data point, given other part of datapoint
predict probability of X_hat_i is ON == first line equation
evaulating at second line, we are assuming alphas are some how given.
example has condition, becaus we assumed conditional order in that way.
sampling is same as assumed way just pick through 1 to 784 orderly.
instead of just using raw input , now it goes in to linear layer, and now we have more parmeters
( which means more flexibility -> more dependecy that model can actually learn)
h is a vector it gets mulitiplied by alpha and sigma and turn into probability.
tie matrix A1 A2 .. single matrix as an W, extract same features for x1
W matrix is shared among iterations.

CAT == categorical distribution , way of representing each probabilty in single term
softmax basically normalize logits and give sum to 1 probability for each logits.

output is no longer binary, categorical distribution. it is now continous probability density function
example means literally mixing multiple Gaussians
cannot use softmax , need to use somthing that gives 2 outputs , mean and variance.

auto encoder = encoding is used for representing data stream as single vectorish notation (compressing)
decoder is to get actual raw value from encoded data
autoencoder is not generative model , it is more to do with representation learning
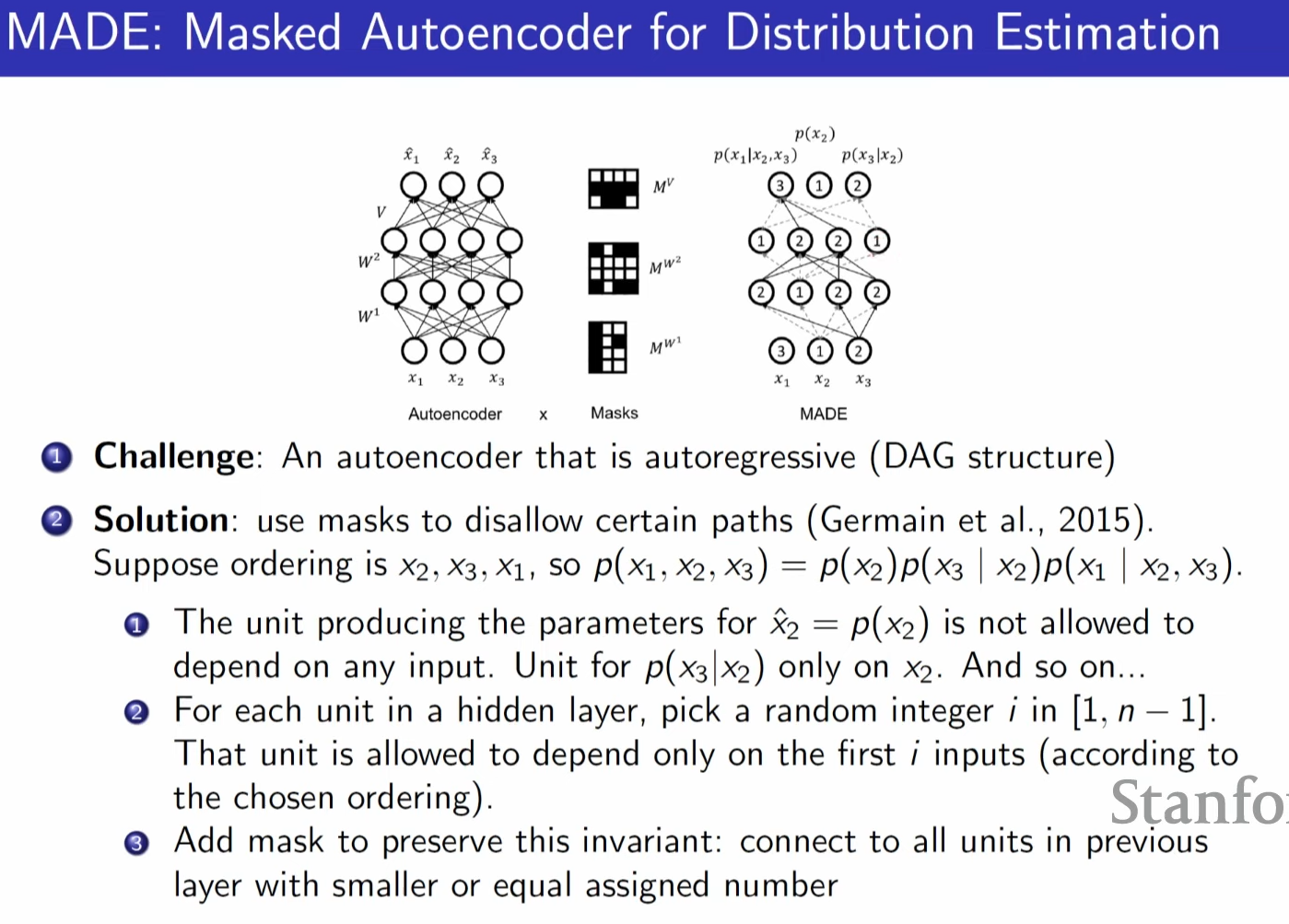
to be autoencoder to be autoregressive it need to amsk some arrows and become DAG structure.

rnn is also autoregressive
'AI > Stanford CS236: Deep Generative Models' 카테고리의 다른 글
| Lecture 7 - Normalizing Flows (0) | 2024.05.26 |
|---|---|
| Lecture 6 - VAEs (0) | 2024.05.23 |
| Lecture 5 - VAEs (0) | 2024.05.21 |
| Lecture 4 - Maximum Likelihood Learning (0) | 2024.05.19 |
| Lecture 2 - Background (0) | 2024.05.17 |