
just trying to optimize our policy even with given 2 bad condition (practical)

infinty norm == just choosing max from given vectors
it doesn't need to converge to optimal , we observe just few n step and evaluate if this is good policy
Performance of AVI

initial error == how far from optimal from my first value function
our n step difference shoud be bounded by those 2 error term
Perfomance of AVI : break down
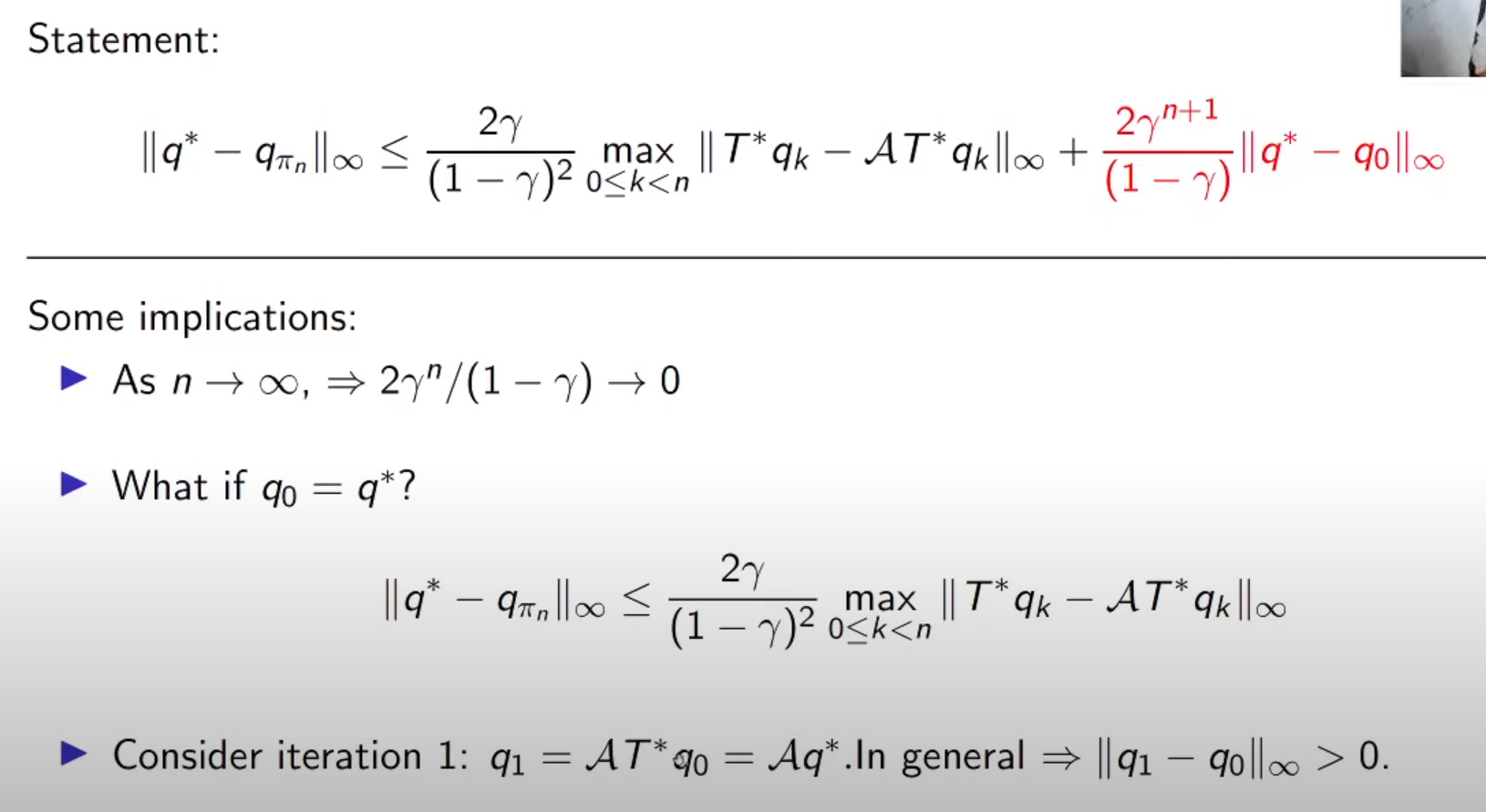
1st line = in the limit we will have no depdency on initialization point
2nd line = even we start with optimal , error term q1-q0 might be not zero due to Approximation A
if intial point is in function approximation error term is going to be zero. but if A is estimation error (instead of having true Bellman operator) like sampling.

init error term goes to zero as r goes to infinity
A is trying to find closest point to g under the L infinity norm
Some concrete instances of AVI
Fitted Q-iteration with Linear Approximation

feature space (pie)

L2 is much easier to optimize
T start would be expectation of Yt
now it is sample square loss rather than true expectation loss
Fitted Q-iteration (gernal receipe)


we can just choose the option and build concrete algorithm

might oscilate but it is bounded (lim superior)

at first line in gain r(s,a) is canceled by each other and remaing term gamma only exist

only infering 3rd term is greater than zero
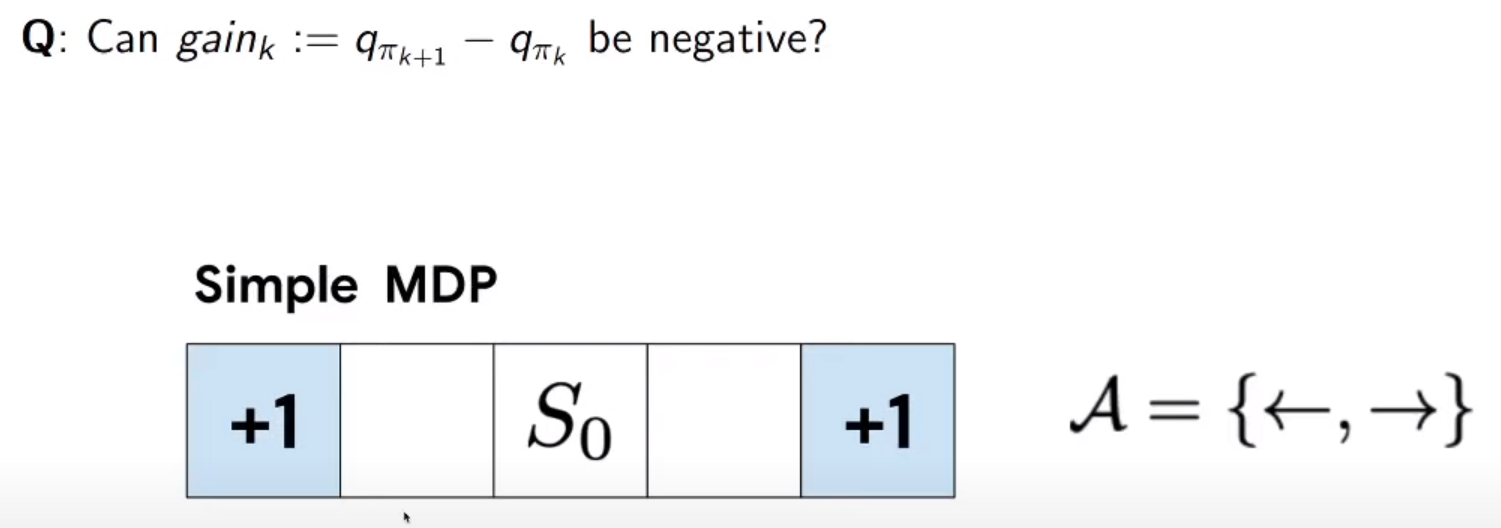

approx qk is made my sample (for exmaple, can be made with some other method)
we derive policy pie(k+1) from approx qk

pie(k+1) s0 should be zero because it cannot never go to terminate state
beside that error it shows we can have minus gain

pie is a value function , L2 with respect to distribution mue^pie (usually stationary distribution with respect to policy pie)
right hand side is best we can do with given hypothesis space (no idea ㅋㅋ)

3rd = qpie is not representable in hypothesis space
FP = fixed point , w* will not be the best apprximation that we can get from "functional class" (it is refering to hypothesis space)
'AI > RL (2021 DeepMind x UCL )' 카테고리의 다른 글
| Lecture 9: Policy-Gradient and Actor-Critic methods (0) | 2022.01.02 |
|---|---|
| Lecture 8: Planning & models (0) | 2021.12.25 |
| Lecture 7: Function Approximation (0) | 2021.12.19 |
| Lecture 6: Model-Free Control (0) | 2021.12.11 |
| Lecture 5: Model-free Prediction (part 2) (0) | 2021.12.04 |