Motiviation
building adult brain is hard but buidling child brain and let it become adult brain might be easier
what is rl
can learn without examples of optimal behaviour

the interaction loop , agent exectue action , agent receive observation.
goal = optimise sum of rewards ,through repeated interaction , a long term goal
2 different goal
1. find solutions
manufacturing robot with a specific purpose, program that plays chess well
2. adapt online, deal with unforeseen circumstances , generalization
chess program that can learn to adapt to you
robot that can learn to navigate unknown terrains

discretime , continuous time also exisit
reward is scalar feedback signal
any goal can be formalized as the outcome of maximizing a cumulative reward = return

the value at some state s is expected 1st reward[Rt+1] you get after being in that state and the value of the state that you expect to be in[v(St+1)]

if the probability of a reward and subsequent state doesn't change if we add more history that decision process is markov
this mean sthat the state contains all we need to know from the history , doesn't mean it contains everything but adding more history won't help
typicall the agent state St is some compression of Ht
agent state can be seen as environment state if fully observable (markov)
Partial observability (not markovian)
a robot with camera vision isn't told its absolute location
the environemnt state can be markov but the agent doesnt know it
Inside the Agent : the policy

value function
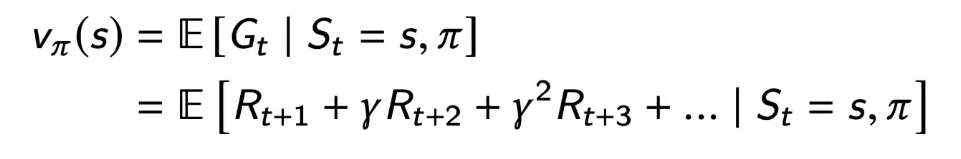
value function depends on policy
discount factor = trades off importance of immediate vs long-term rewards
if zero only cares about immediate , if one all rewards are going to be important.
model
predicts what the environment will do next
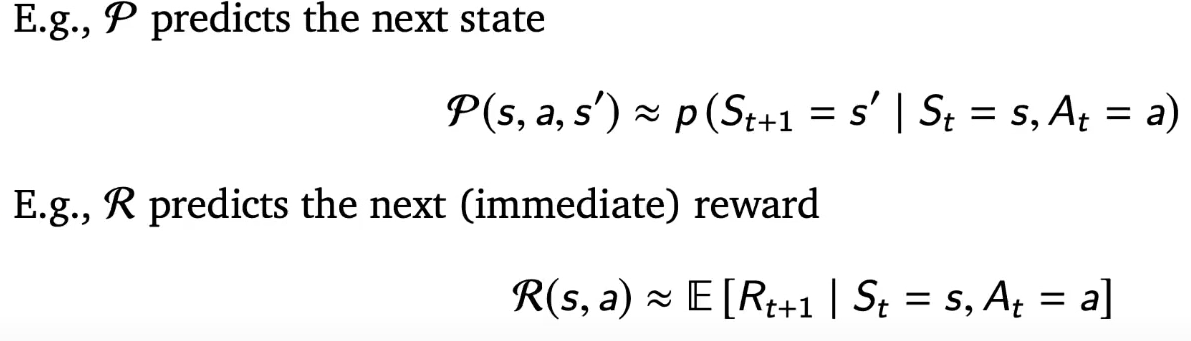
agent categories
value based = no policy, depends on value function
policy based = no value function , just explict policy
actor critic = policy exist , value function is used to update that policy in some way
model free = have policy or value function , but no model
model based = does have model
subproblems of RL
prediction = evaluate the future (for a given policy)
control = optimise the future (find the best policy)

2 things are strongly related , if we have good prediction we can use it to find good policy
'AI > RL (2021 DeepMind x UCL )' 카테고리의 다른 글
| Lecture 5: Model-free Prediction (part 1) (0) | 2021.12.04 |
|---|---|
| Lecture 4: Theoretical Fund. of Dynamic Programming Algorithms (0) | 2021.11.27 |
| Lecture 3: MDPs and Dynamic Programming (0) | 2021.11.20 |
| Lecture 2: Exploration and Exploitation (part 2) (0) | 2021.11.14 |
| Lecture 2: Exploration and Exploitation (part 1) (0) | 2021.11.13 |