Universal Hashing
choose a random hash function h(function) from H(set)
require H(set) tobe a universal hashing family such that
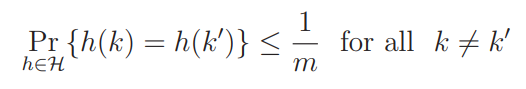
Theorem = For n arbitrary distinct keys and random h(function) from H(set) , where H(set) is a universal hashing family

here I is indicator random variable. by computing expectation of I(i,j) is less than 1/m because h is from universal hashfunction family(set)
E[I(i,i)] is always 1 because it will always map to same slot.
Dot product hash family
m is prime , u = m^r where r is integer.

computing ha(k) takes constant time because we are assuming word RAM model
Word RAM model = any integer that is size of word , and with constant number of words we can do any operation in constant time.
by choosing a randomly we can achieve universality of hash funciton

we are using expectation to remove other randomness (a0 ,a1 a2.. ar). we are missing mod m when we use expectation.
with Mod m , 1/u becomes 1/m because we are choosing a randomly.
Perfect Hashing (no insert or delete)
O(1) for search , O(n) space both in worst case , polynomial build time With High Probability

Step1 = Pick h1 from universal hash family that maps {0,1,... u-1} to {0,1,...,m-1}
Step 1.5 = if sum of squared number of items in slot j (0~m-1) is bigger than cn (c is chosen constant) we redo Step1
Step 2 = for each slot j (0~m-1) pick h(2,j) from universal hash family that maps {0,1, ... u-1} to {0, 1 , ... mj} where mj size is simliar to squared # of items in slot j.
Step 2.5 = if h(2,j) makes collision repick h(2,j) and do step2 again
first we prove how much time it takes to do step 2.5

l(j) = number of items in slot j. union bound , because there might be many other keys that will collide beside key(i) so summing all probability of that key colliding will be bigger.
we choose among possilbe collsion key == (l(j) 2)
by universality == 1/m == 1/ l(j) ^2
zero collsion will happen at least 50% , expected number of trial until we get zero collsion hash function h(2,j) is 2.
just like in skip List (WITH HIGH PROBABILITY)
Randomization: Skip Lists (tistory.com)
Randomization: Skip Lists
Search(x) in case for level 2 walk right in top linked list walk down to bottom linked list walk right if it is last row linked list In general case Search will take O(logn) Insert(x) do Search(x)..
tonylim.tistory.com
then total time to do step 2 and step 2.5 is O(N) [size of first hash table , we need to h2 for all slot] * O(logn) [size of l(j)] * O(logn) [expected nubmer of trial] == O(Nlog^2N)

n == for same i and i`
(n 2) == choosing 2 from n keys but orders matter so we multiply by 2
1/m == universality

picture is wrong the first inequality sign need to be reversed
probability of seocnd hash table size is bigger than cn is less than half
expected number of trial until we get table size less than cn is O(logn)
total time cost to do step 1 and step 1.5 == O(n) [time to hash all n keys] * O(nlogn) [repeat time] == O(nlogn)
'Algorithm > Design and Analysis of Algorithms' 카테고리의 다른 글
| Dynamic Programming: Advanced DP (0) | 2021.11.07 |
|---|---|
| Augmentation: Range Trees , B-Tree (0) | 2021.10.14 |
| Randomization: Skip Lists (0) | 2021.05.24 |
| Randomization: Matrix Multiply Checker, Quicksort (0) | 2021.05.19 |
| Text justification (0) | 2021.01.24 |