
One hot vector representation , each column represent single word = impossible to represent all words
there is no similarity for one hot vectors. (orthogonal)
Distributional semantics = A word's meaning is given by the words that frequently appear close-by
Word2Vec
given some window size , iterate through sentence and update the word vectors

given center word algorithm tries to predict word that is close to center word which is in window size.

first product meaning will go through all the texts and second means will iterate through given window size.
only parameter here which is theta , are word vectors.
In objective function T is for scaling factor.
Log is known to be good empirically

we use 2 vectors for convenience. u for context word. v for center word.
upper part is calculating inner product with outside word vector and center word vector
lower part is for normalizing
softmax

exp makes large x bigger and there will be no zero.
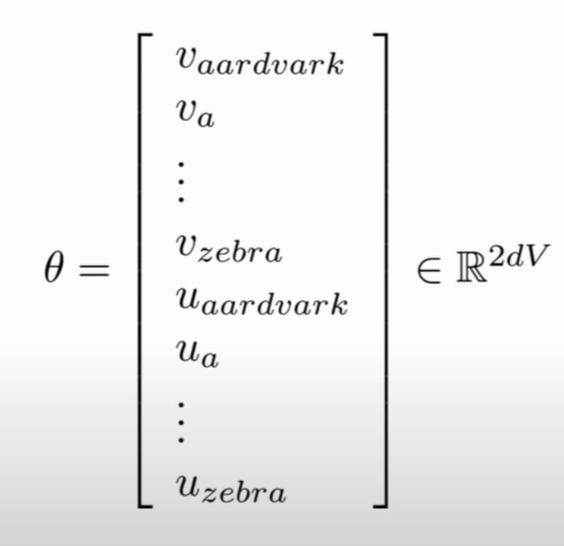
every word has 2 vector(u,v) that is why dimension is 2dV and this theta is only parameter we have.
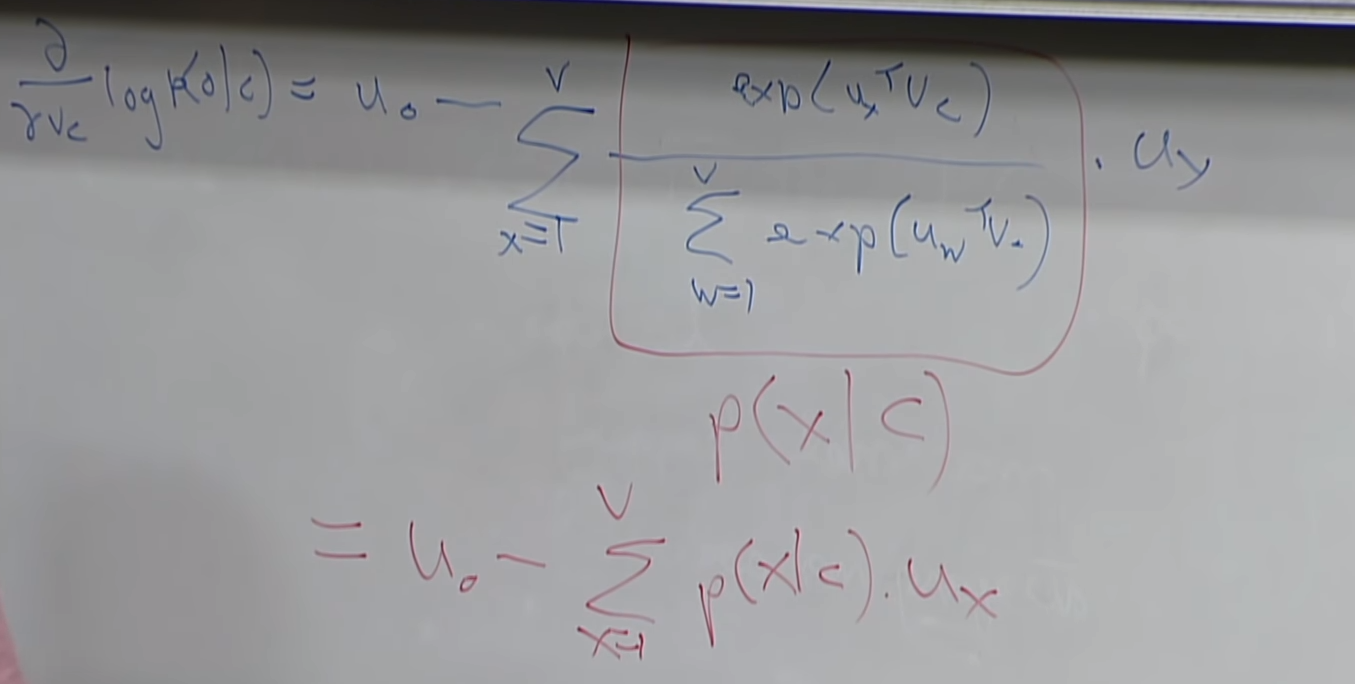
after all the Derivative we have our solution meaning , in order to minmize our loss we need to go this way which is minmizing given acutal outside word vector minus expected outside word vector.
'AI > NLP (cs224n)' 카테고리의 다른 글
| Lec6) Language Models and RNNs (0) | 2021.04.27 |
|---|---|
| Lec5) Dependency Parsing , Optimizer(GD to ADAM) (0) | 2021.04.26 |
| Lec4) NLP with Deep Learning (0) | 2021.04.13 |
| Lec3) Neural Networks (0) | 2021.04.12 |
| Lec2) Word Vectors and Word Senses (0) | 2021.04.06 |