
instead of doing each word error , we calculate windows error and later on we split into (in this case 5) 5 and update our word vector.


this things might happen when we fine tune our pretrained word vectors. so what shoudl we do?
we only "fine tune" my own word vector when we have only large training dataset. most of the time just using pretrained word vectors are best.

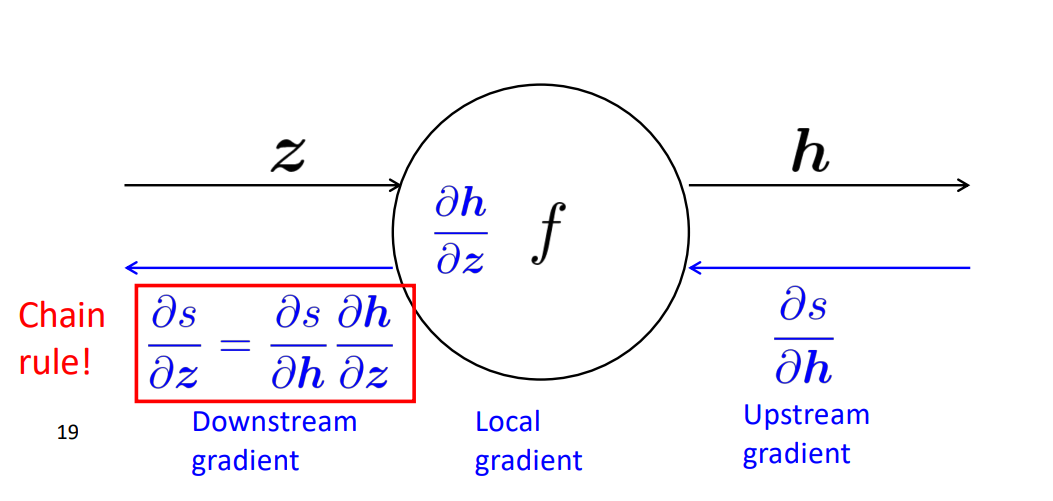
our goal is to calculate "Downstream Gradient" and we can do that by using chain rule with Local gradient and upstream gradient.
we skipped the very final one because derivative s by s is just 1. this case is where # of input and ouput is 1 we want general case.

same chain rule computation but doing it for each input.

when we have more than one back prop gradients , in this case y , we just add them up.
Things to remember in deep learning
1.Reugularization

to prevents overfitting otherwise model will only good for trained data.
2. Vectorization
in order to make use of GPU we need to vectorrize and matrix
3. Current Best Non Linearity = RELU

4. Parameter Initalization
never start with all zeros. always intitalize with some small random value.
5. Optimziers
SGD is fine but there are many others. Adam is one of them
6. Learning Rate
Better results can generally be obtained by allowing learning rates to decrease as you train
'AI > NLP (cs224n)' 카테고리의 다른 글
| Lec6) Language Models and RNNs (0) | 2021.04.27 |
|---|---|
| Lec5) Dependency Parsing , Optimizer(GD to ADAM) (0) | 2021.04.26 |
| Lec3) Neural Networks (0) | 2021.04.12 |
| Lec2) Word Vectors and Word Senses (0) | 2021.04.06 |
| Lec1) introduction and Word vectors (0) | 2021.04.05 |