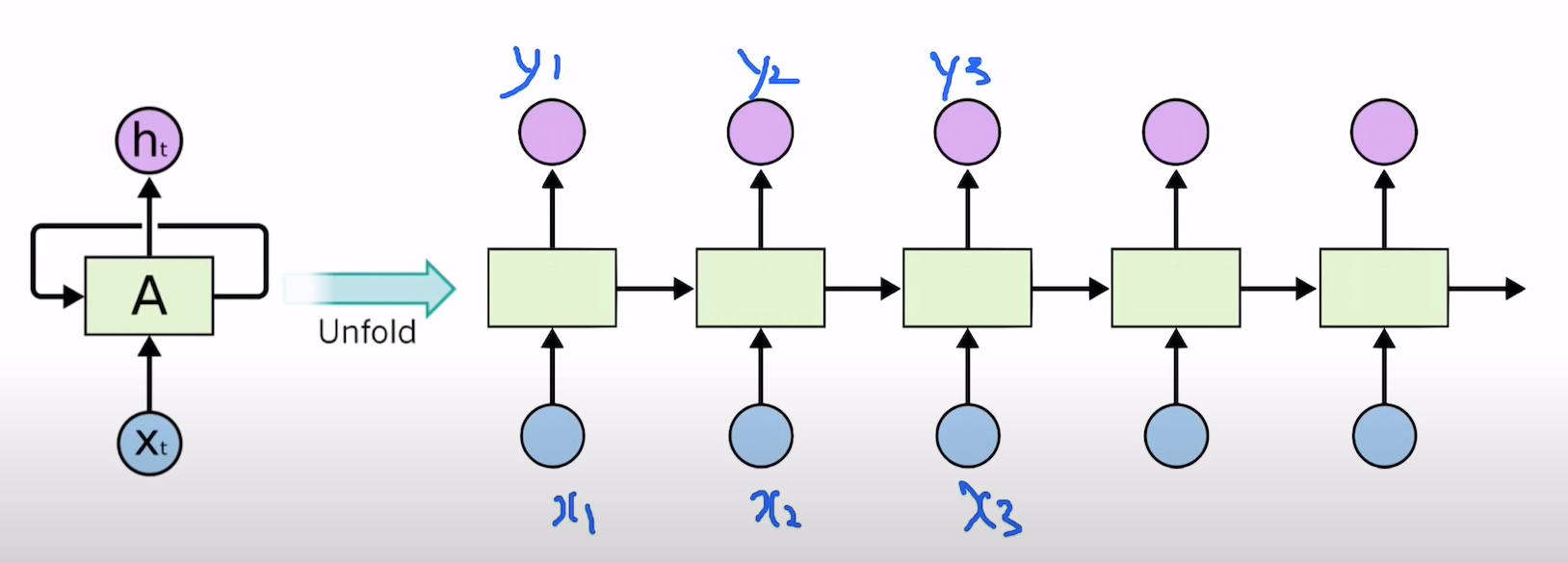
h = [1, 0, 0, 0]
e = [0, 1, 0, 0]
l = [0, 0, 1, 0]
o = [0, 0, 0, 1]
# One cell RNN input_dim (4) -> output_dim (2). sequence: 5
cell = nn.RNN(input_size=4, hidden_size=2, batch_first=True)
# (num_layers * num_directions, batch, hidden_size) whether batch_first=True or False
hidden = torch.randn(1, 1, 2)
# Propagate input through RNN
# Input: (batch, seq_len, input_size) when batch_first=True
inputs = torch.Tensor([h, e, l, l, o])
for one in inputs:
one = one.view(1, 1, -1)
# Input: (batch, seq_len, input_size) when batch_first=True
out, hidden = cell(one, hidden)
print("one input size", one.size(), "out size", out.size())we can do training with iteration. we first initialize hidden vector and then put it in RNN with input
notice the hidden size == num_layers means that we can have mutiple layers , num_directions means we can have bidrectional RNN
output and hidden will be same since we are only using 1 layer with mutiple layer output result will last depth of hidden state
What's the difference between "hidden" and "output" in PyTorch LSTM?
I'm having trouble understanding the documentation for PyTorch's LSTM module (and also RNN and GRU, which are similar). Regarding the outputs, it says: Outputs: output, (h_n, c_n) output (
stackoverflow.com
inputs = inputs.view(1, 5, -1)
out, hidden = cell(inputs, hidden)
print("sequence input size", inputs.size(), "out size", out.size())we can do it above things in one line by setting "seq_len" to 5.
input means we are having 1 batch that contains 5 of word vectors which have size -1 (automatically calculate word vector size in our case it is 4)
hidden = torch.randn(1, 3, 2)
inputs = torch.Tensor([[h, e, l, l, o],
[e, o, l, l, l],
[l, l, e, e, l]])
out, hidden = cell(inputs, hidden)
print("batch input size", inputs.size(), "out size", out.size())now we are using hidden tensor size = one layer * single direction , 3 batch , hidden size = 2
inputs tensor size = 3 batch size , 5 sequence length , each variable has vetor 4
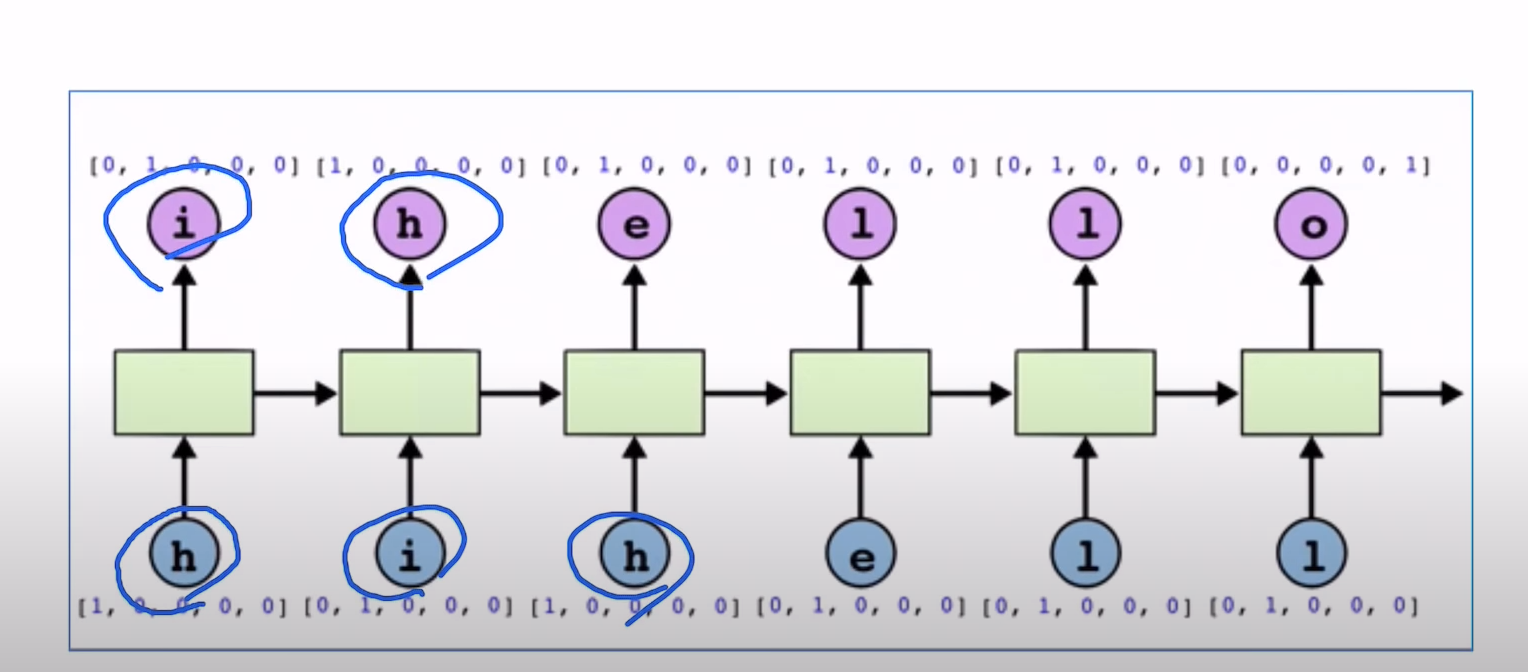
trying to teach RNN something like language modeling. we want RNN to predict if we give "hihell" then say "ihello".
idx2char = ['h', 'i', 'e', 'l', 'o']
# Teach hihell -> ihello
x_data = [0, 1, 0, 2, 3, 3] # hihell
one_hot_lookup = [[1, 0, 0, 0, 0], # 0
[0, 1, 0, 0, 0], # 1
[0, 0, 1, 0, 0], # 2
[0, 0, 0, 1, 0], # 3
[0, 0, 0, 0, 1]] # 4
y_data = [1, 0, 2, 3, 3, 4] # ihello
x_one_hot = [one_hot_lookup[x] for x in x_data]
# As we have one batch of samples, we will change them to variables only once
inputs = Variable(torch.Tensor(x_one_hot))
labels = Variable(torch.LongTensor(y_data))we used one hot vector encoding table.
num_classes = 5
input_size = 5 # one-hot size
hidden_size = 5 # output from the RNN. 5 to directly predict one-hot
batch_size = 1 # one sentence
sequence_length = 1 # One by one
num_layers = 1 # one-layer rnn
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.rnn = nn.RNN(input_size=input_size,
hidden_size=hidden_size, batch_first=True)
def forward(self, hidden, x):
# Reshape input (batch first)
x = x.view(batch_size, sequence_length, input_size)
# Propagate input through RNN
# Input: (batch, seq_len, input_size)
# hidden: (num_layers * num_directions, batch, hidden_size)
out, hidden = self.rnn(x, hidden)
return hidden, out.view(-1, num_classes)
def init_hidden(self):
# Initialize hidden and cell states
# (num_layers * num_directions, batch, hidden_size)
return Variable(torch.zeros(num_layers, batch_size, hidden_size))input_size and output_size are same because we are going to put our output to next input.
x.view allows you to put the entire "hihell" rather than just one character.
once we get our ouput we need to compute with true "y" and compute loss. so we need to make output same as true "y" size using view
model = Model()
print(model)
# Set loss and optimizer function
# CrossEntropyLoss = LogSoftmax + NLLLoss
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.1)
# Train the model
for epoch in range(100):
optimizer.zero_grad()
loss = 0
hidden = model.init_hidden()
sys.stdout.write("predicted string: ")
for input, label in zip(inputs, labels):
# print(input.size(), label.size())
hidden, output = model(hidden, input)
val, idx = output.max(1)
sys.stdout.write(idx2char[idx.data[0]])
loss += criterion(output, torch.LongTensor([label]))
print(", epoch: %d, loss: %1.3f" % (epoch + 1, loss))
loss.backward()
optimizer.step()for every epoch we init our hidden because at first we don't have any initial hidden state so we just give it randomly. notice it doesn't affect learning of other hidden state it is just first hidden state that contains no information.
'AI > Pytorch' 카테고리의 다른 글
| pytorchZeroToAll) RNN 2 Classification (0) | 2021.05.09 |
|---|---|
| pytorchZeroToAll) CNN , Advanced CNN(inception) (0) | 2021.04.29 |
| pytorchZeroToAll) Linear ,Logistic , Wide and Deep (0) | 2021.04.24 |