convolution use kernel matrix(filter) as weight parameter (keep changes as training goes on)
with RGB (depth =3 ) picture we use kernel matrix depth 3
we can have mutiple kernel matrix and create depth of activation maps (feature maps)

28 comes from 5*5 , 6 comes from using 6 filters and all fiters have same depth as input
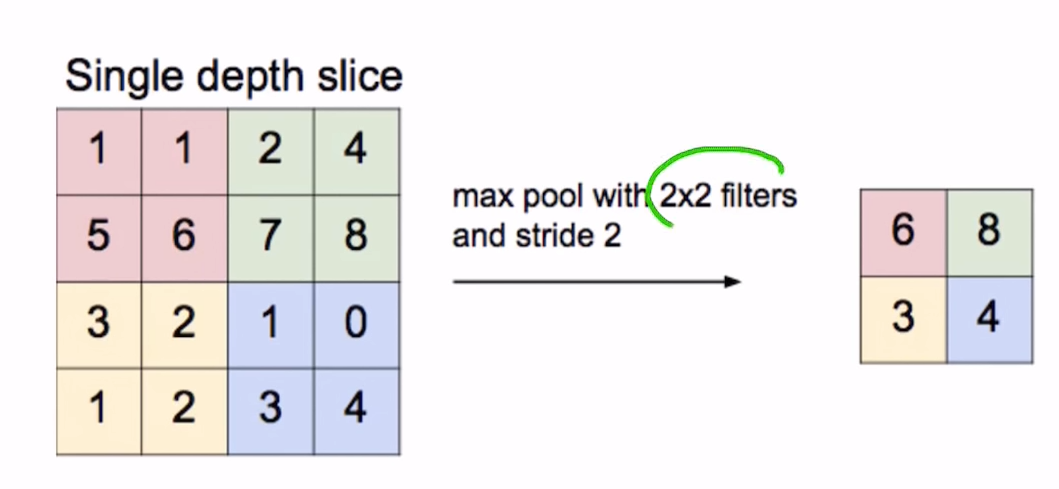
max pooling
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.mp = nn.MaxPool2d(2)
self.fc = nn.Linear(320, 10)
def forward(self, x):
in_size = x.size(0)
x = F.relu(self.mp(self.conv1(x)))
x = F.relu(self.mp(self.conv2(x)))
x = x.view(in_size, -1) # flatten the tensor
x = self.fc(x)
return F.log_softmax(x)
model = Net()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
def train(epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = Variable(data), Variable(target)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % 10 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))if your not sure about size of fully connected layer (nn.Linear(?,10) ) just put any random nubmer and Error will popup like below then you can fix it.
RuntimeError: mat1 and mat2 shapes cannot be multiplied (64x320 and 3201x10)
Advanced CNN (Inception)

using 1*1 convolution we can reduce depth and maintain size eventually reducing computation.

class InceptionA(nn.Module):
def __init__(self, in_channels):
super(InceptionA, self).__init__()
self.branch1x1 = nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch5x5_1 = nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch5x5_2 = nn.Conv2d(16, 24, kernel_size=5, padding=2)
self.branch3x3dbl_1 = nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch3x3dbl_2 = nn.Conv2d(16, 24, kernel_size=3, padding=1)
self.branch3x3dbl_3 = nn.Conv2d(24, 24, kernel_size=3, padding=1)
self.branch_pool = nn.Conv2d(in_channels, 24, kernel_size=1)
def forward(self, x):
branch1x1 = self.branch1x1(x)
branch5x5 = self.branch5x5_1(x)
branch5x5 = self.branch5x5_2(branch5x5)
branch3x3dbl = self.branch3x3dbl_1(x)
branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)
branch3x3dbl = self.branch3x3dbl_3(branch3x3dbl)
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
branch_pool = self.branch_pool(branch_pool)
outputs = [branch1x1, branch5x5, branch3x3dbl, branch_pool]
return torch.cat(outputs, 1)after going through each layer and concatenate all the result
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(88, 20, kernel_size=5)
self.incept1 = InceptionA(in_channels=10)
self.incept2 = InceptionA(in_channels=20)
self.mp = nn.MaxPool2d(2)
self.fc = nn.Linear(1408, 10)
def forward(self, x):
in_size = x.size(0)
x = F.relu(self.mp(self.conv1(x)))
x = self.incept1(x)
x = F.relu(self.mp(self.conv2(x)))
x = self.incept2(x)
x = x.view(in_size, -1) # flatten the tensor
x = self.fc(x)
return F.log_softmax(x)
model = Net()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
def train(epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = Variable(data), Variable(target)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % 10 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.data[0]))we can use above inception twice and create Simple CNN + Inception. but can we just keep on adding inception or new layer and make our network deeper and wider?

No error tend to be high for deeper layer if depth cross certain threshold.
- Vansishing gradients problem
- degradation problem = with increased network depth accuracy gets saturated and then rapidly degrades.
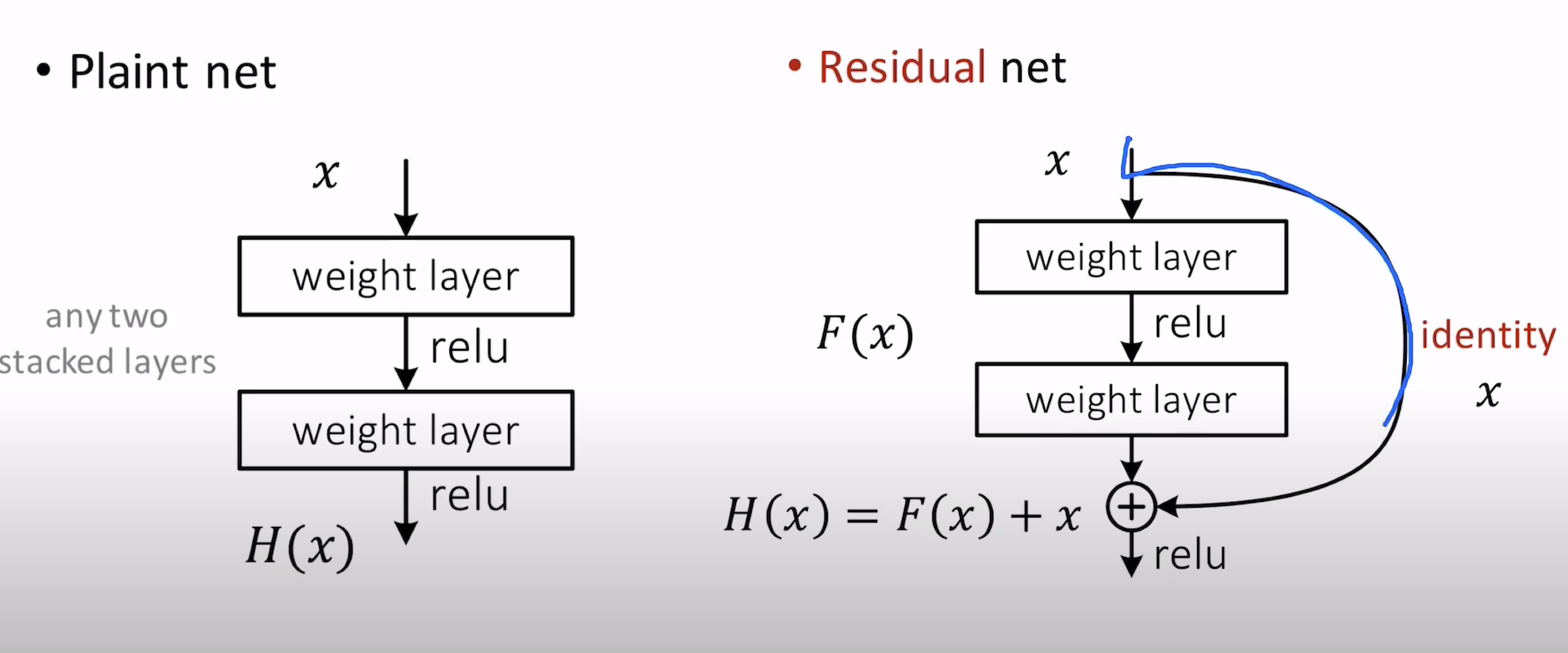
solution for vanishing problem we add "identity x" to keep reference old data.
'AI > Pytorch' 카테고리의 다른 글
| pytorchZeroToAll) RNN 2 Classification (0) | 2021.05.09 |
|---|---|
| pytorchZeroToAll) RNN1 (0) | 2021.05.06 |
| pytorchZeroToAll) Linear ,Logistic , Wide and Deep (0) | 2021.04.24 |