pytorch basic pattern
1. Design your model using class with Variables
2. Construct loss and optimzier (select form Pytorch API)
3. Training Cycle (1.forward , 2.backward , 3.update)
Linear regression
import torch.nn.functional
from torch import tensor
from torch import nn
x_data = tensor([[1.0],[2.0],[3.0]])
y_data = tensor([[2.0],[4.0],[6.0]])
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear = nn.Linear(1,1)
def forward(self,x):
y_pred = self.linear(x)
return y_pred
model = Model()
criterion = nn.MSELoss(reduction='sum')
optimizer = torch.optim.SGD(model.parameters(),lr=0.01)
for epoch in range(500):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(f'Epoch: {epoch} | Loss: {loss.item()}')
optimizer.zero_grad()
loss.backward()
optimizer.step()
hour_var = tensor([4.0])
y_pred = model(hour_var)
print("Predicted score (after training)", "4 hours of studying: ", model(hour_var).data[0].item())Notice every time we train we need to zero_grad our gradients because in pytorch gradient gets keep accumulated.
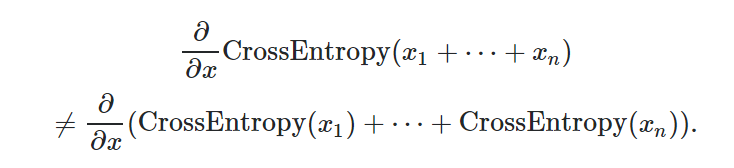
Inside loss function reduction term has some options like sum , mean. if it is set to none which is default it will compute as firstone. and sum,mean will compute as below.
Logistic regression with sigmoid at the end
import torch.nn.functional as F
import torch.optim as optim
import torch
from torch import tensor
from torch import nn
from torch import sigmoid
x_data = tensor([[1.0],[2.0],[3.0],[4.0]])
y_data = tensor([[0.],[0.],[1.],[1.]])
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear = nn.Linear(1,1)
def forward(self,x):
y_pred = sigmoid(self.linear(x))
return y_pred
model = Model()
criterion = nn.BCELoss(reduction='mean')
optimizer = optim.SGD(model.parameters(),lr=0.01)
for epoch in range(500):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(f'Epoch: {epoch} | Loss: {loss.item():.4f}')
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f'\nLet\'s predict the hours need to score above 50%\n{"=" * 50}')
hour_var = model(tensor([[1.0]]))
print(f'Prediction after 1 hour of training: {hour_var.item():.4f} | Above 50%: {hour_var.item() > 0.5}')
hour_var = model(tensor([[7.0]]))
print(f'Prediction after 7 hours of training: {hour_var.item():.4f} | Above 50%: { hour_var.item() > 0.5}')BCE is Binary Cross Entropy Loss which is good for binary regression , which has output case 1 or 0.
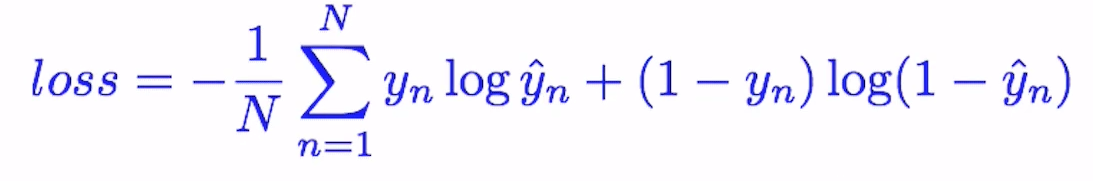
it is good for binary regression because if true y is 1 than we igonore right term and compute our prediction with log average.
if true y is zero we ignore our left term and compute log average term of our prediction
we used sigmoid as our activation function there are many others like RELU
from torch import nn, optim, from_numpy
import numpy as np
xy = np.loadtxt('./data/diabetes.csv.gz', delimiter=',', dtype=np.float32)
x_data = from_numpy(xy[:, 0:-1])
y_data = from_numpy(xy[:, [-1]])
print(f'X\'s shape: {x_data.shape} | Y\'s shape: {y_data.shape}')
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.l1 = nn.Linear(8, 6)
self.l2 = nn.Linear(6, 4)
self.l3 = nn.Linear(4, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
out1 = self.sigmoid(self.l1(x))
out2 = self.sigmoid(self.l2(out1))
y_pred = self.sigmoid(self.l3(out2))
return y_pred
model = Model()
criterion = nn.BCELoss(reduction='mean')
optimizer = optim.SGD(model.parameters(), lr=0.1)
for epoch in range(100):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(f'Epoch: {epoch + 1}/100 | Loss: {loss.item():.4f}')
optimizer.zero_grad()
loss.backward()
optimizer.step()we have width 8 since there are 8 categories indicating wether someone has diabetes.
we have depth 3 because we initialize our model with 3 Linear layer. one thing to consider is input and ouptsize of Layers
The first layer has 8 inputs and the last layer eventually has 1 output. This output determines whether the predicted outcome is diabetes or not.
Notice when Layer goes deeper "Vanishing Gradient Problem" happens. In order to weaken this we can use different activation function like RELU.
'AI > Pytorch' 카테고리의 다른 글
| pytorchZeroToAll) RNN 2 Classification (0) | 2021.05.09 |
|---|---|
| pytorchZeroToAll) RNN1 (0) | 2021.05.06 |
| pytorchZeroToAll) CNN , Advanced CNN(inception) (0) | 2021.04.29 |