
각각의 instance가 각각의 db를 가지고 있고 뭔가 변화가 일어날때마다 mQ에 보내서 동기화를 맞춰주는 방법이다.

여러개의 MS instance가 떠도 하나의 db instance로 동기화를 맞춰준다. kafka가 순서를 보장해주던가..?
kafka

producer , cosumer 는 각각 어떤 플랫폼이나 서비스가 받거나 생산할건지 고려하지 않고 오직 카프카만 집중하여 자신들의 보내거나 소비하고 싶은 데이터를 맡기면 된다.
kafka install
https://kafka.apache.org/quickstart
Apache Kafka
Apache Kafka: A Distributed Streaming Platform.
kafka.apache.org
wsl2 환경에 동일하게 잘 적용된다.

예제도 잘 동작하는 것을 확인
producer가 만든 event(message) 는 topic (quickstart-events)에 저장이 되고 consumer는 해당 topic에서 message를 꺼내간다.
동시에 여러개의 consumer가 있다 하더라도 처음 부터 (--from-begnning) 다 동일하게 받아올 수 있다.
https://github.com/joneconsulting/msa_with_spring_cloud/tree/main/docker-files
GitHub - joneconsulting/msa_with_spring_cloud
Contribute to joneconsulting/msa_with_spring_cloud development by creating an account on GitHub.
github.com
도커로도 카프카를 테스트 해볼 수 있다.
kafka connect

restapi 형식으로 지원하고 알맞은 connector 를 설치 해야한다.
curl -O http://packages.confluent.io/archive/6.1/confluent-community-6.1.0.tar.gz
tar xvf confluent-community-6.1.0.tar.gz위 과정을 통해 Kafka Connect 를 먼저 설치한다.
- https://docs.confluent.io/5.5.1/connect/kafka-connect-jdbc/index.html
- confluentinc-kafka-connect-jdbc-10.0.1.zip그리고 실습에서 쓸 mysql driver와 이를 연결해줄 JDBC Connector 를 설치한다.
plugin.path=/home/tony/vscode/spring-cloud/kafka/confluentinc-kafka-connect-jdbc-10.6.0/lib해당 JDBC Connector zip 파일을 unzip 해준후에 {kafka-connect경로}.\etc\kafka\connect-distributed.properties 파일에서 plugin.path에 경로를 바꿔치기한다.
{kafka-connect 경로}.\share\java\kafka\ 에 mysql driver를 복사해준다.
https://docs.confluent.io/platform/current/connect/references/restapi.html
Connect REST Interface | Confluent Documentation
Since Kafka Connect is intended to be run as a service, it also supports a REST API for managing connectors. By default this service runs on port 8083. When executed in distributed mode, the REST API will be the primary interface to the cluster. You can ma
docs.confluent.io

위 rest api 를 참고하여서 source connector를 추가할 수 있다. 위 사진의 예시는 이미 만들어진 source conector를 modify 하는 api 를 호출한 것이다.

이제 mysql db 에서 위에 명시된 테이블에 insert 문을 날리면 그것이 kafka topic (my_topic_integer_table) 에 저장이 된고 Consumer에서 소비할 수 있게 된다.
Sink Connector
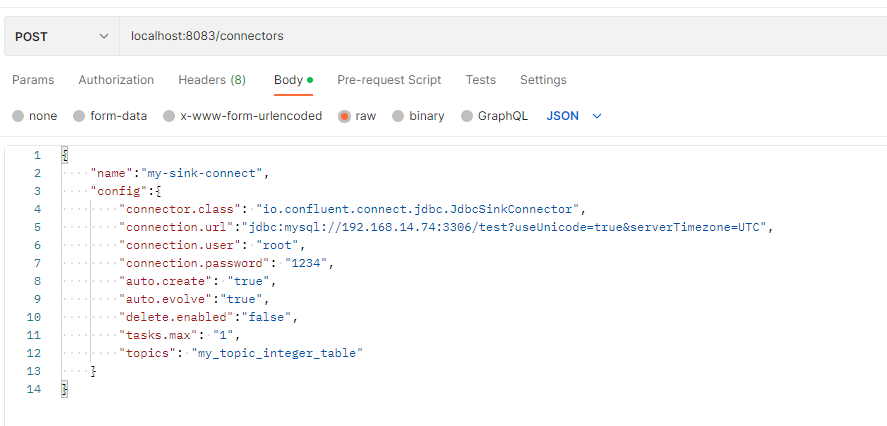
connector class 이름을 JdbcSinkConnector로 해줘야한다.
이게 제대로 등록이 되면 topics 에 적힌 topic을 받아들이는 테이블이 (my_topic_integer_table 테이블 명으로 )
mysql 에 생성된다.

기존 source connect랑 연결되어있는 integer_table에 insert 로 3을 넣어주면
consumer에서도 해당 topic 을 소비할 수 있고 sink connect 랑 연결되어있는 my_topic_integer_table에서도 해당 토픽을 받아들여서 select로 조회시 추가 된것 을 확인 할 수 있다.

kafka console producer에서 jdbc connector에 알맞은 json을 입력하면 이것이 지정한 topic으로 저장되고 consumer와 sink connect에서 소비한다.
'Cloud > SpringCloud로 개발하는 MSA' 카테고리의 다른 글
| 장애 처리와 MS 분산 추적 (0) | 2022.11.04 |
|---|---|
| MS간의 data 동기화 (2. kafka 응용) (1) | 2022.11.03 |
| MS간 통신 (0) | 2022.10.29 |
| gateway 인증 + Cloud Config + Cloud Bus(rabbitMQ) + 암호화 (0) | 2022.10.28 |
| API Gateway Service (0) | 2022.10.14 |