
unlike other RNN, LSTM we can some how tell decoder to where you should focus (attention)

positional encoding = gives network significant boost for performance
top right attention = 3 connection going into it (key, value = encoding part of source sentence) , (query = encoding part of target sentence)

dot product of keys and query = gives angles between these 2 vecotors , if both of them are pointing to same direction result will be large
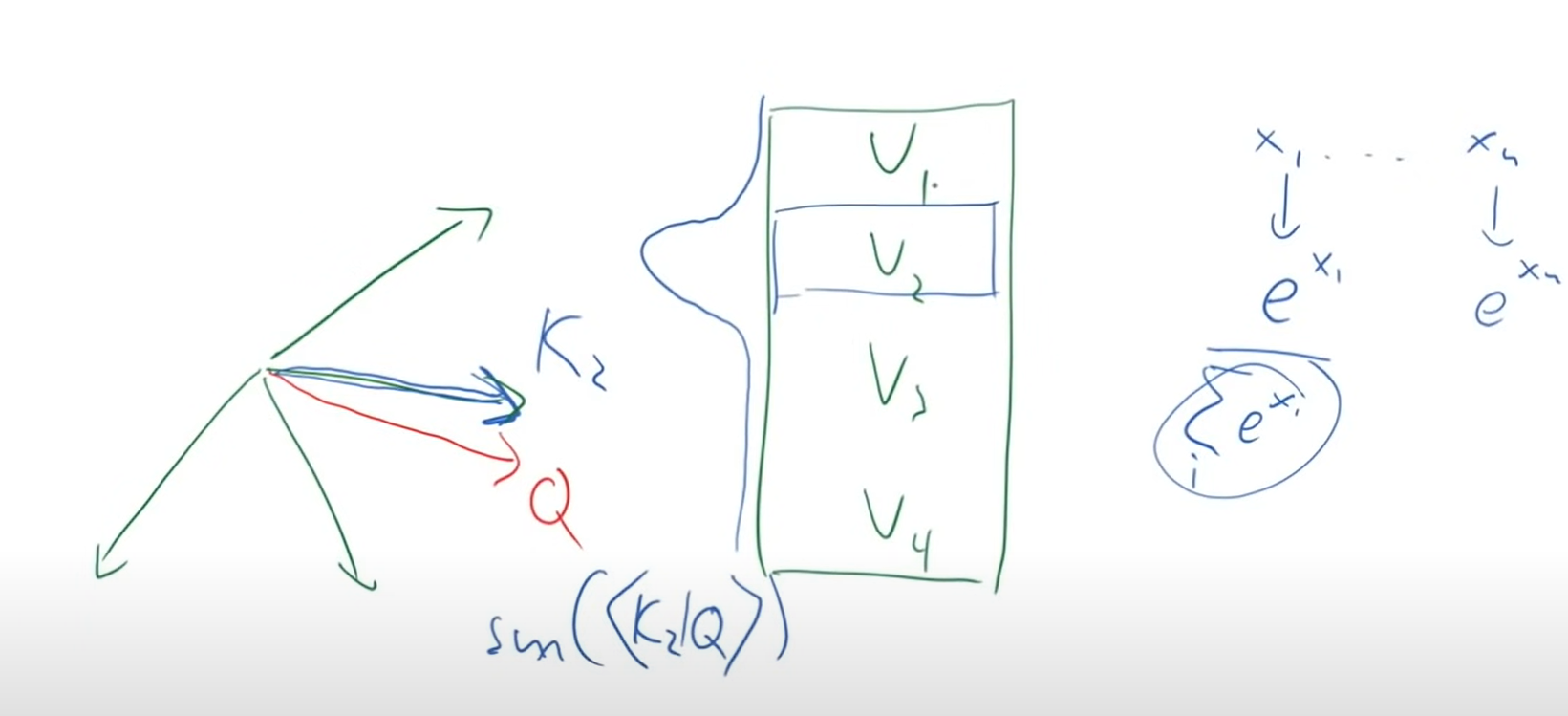
by doing softmax on dot product we can index V2(value for K2) , the most relevant soruce token

V is bunch of information that we might find intersting about soruce and K is representation(index, address) of each value
Query = i would like to know certain thing, like name, height something like this , we can find it by dot product with key and doing softmax we can find matching V(value, [name, height ..])