

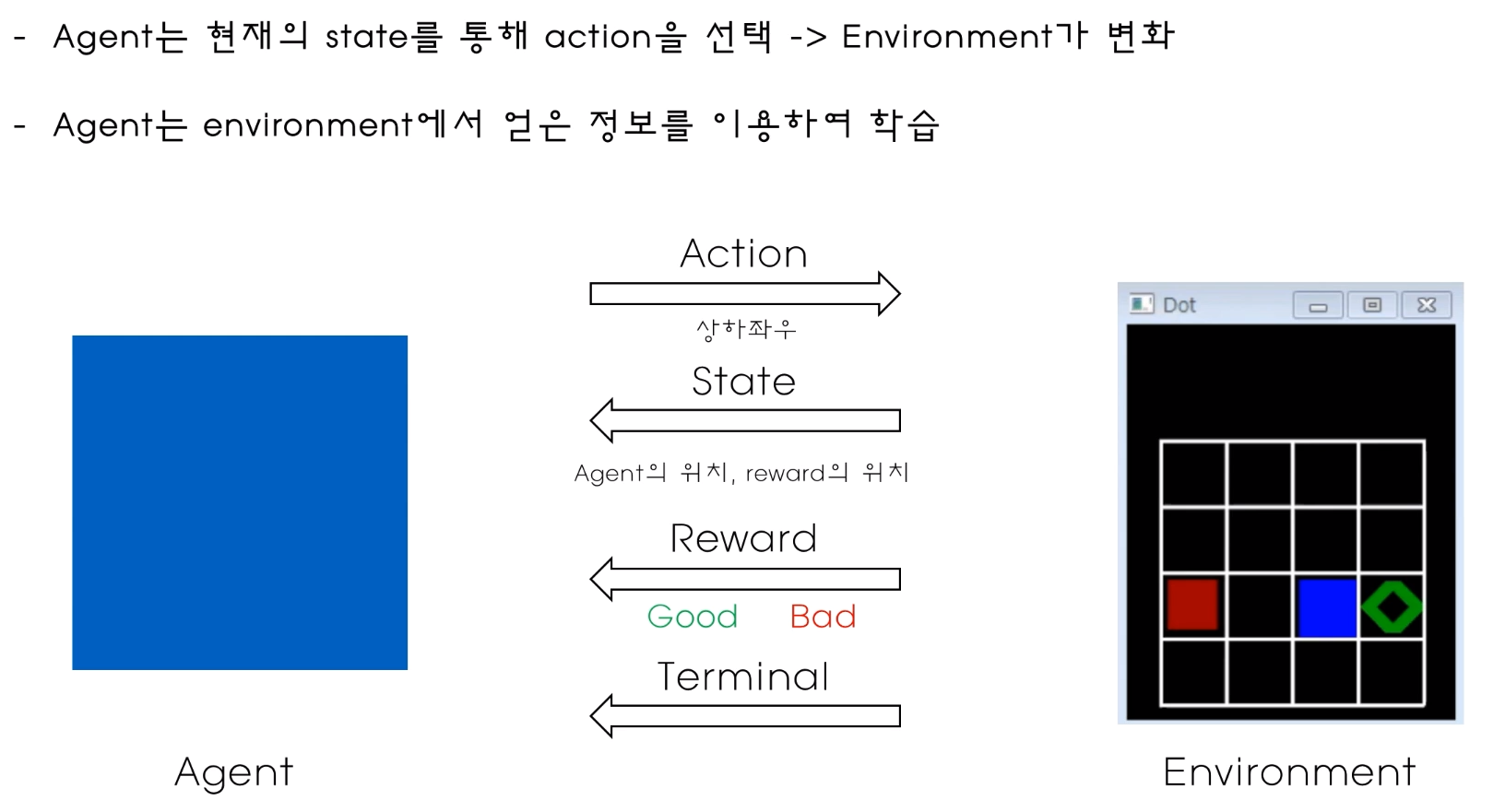

각 state에서 어떤 액션을 취하는게 좋은것인지를 각각의 Q 값을 통해 알수있다. 학습이 잘되어있는 경우에는
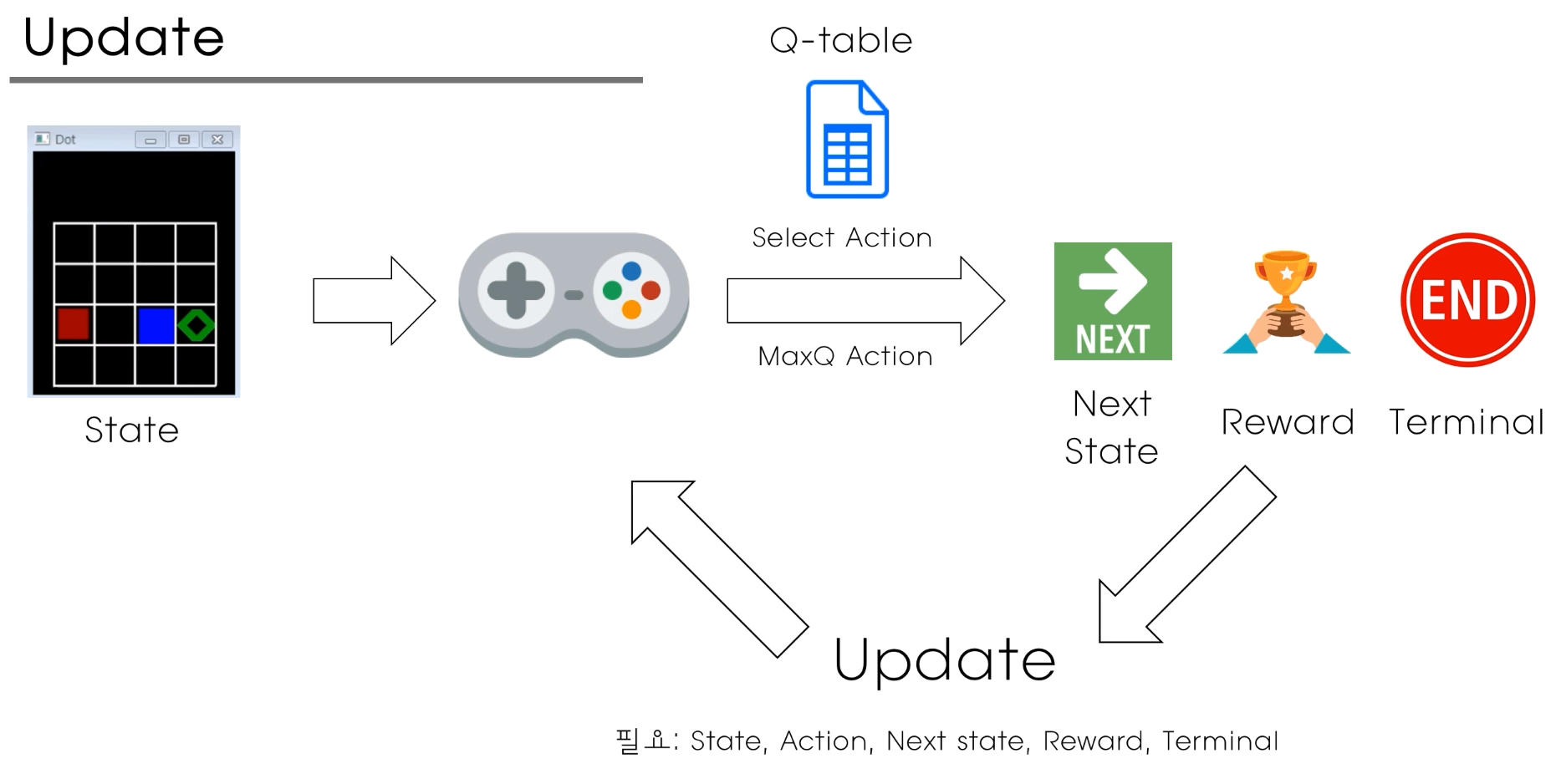
하지만 Q table은 처음부터 정답을 알려주지 않는다. 학습을 계속 반복적으로 수행해가면서 쓸만하게 된다.


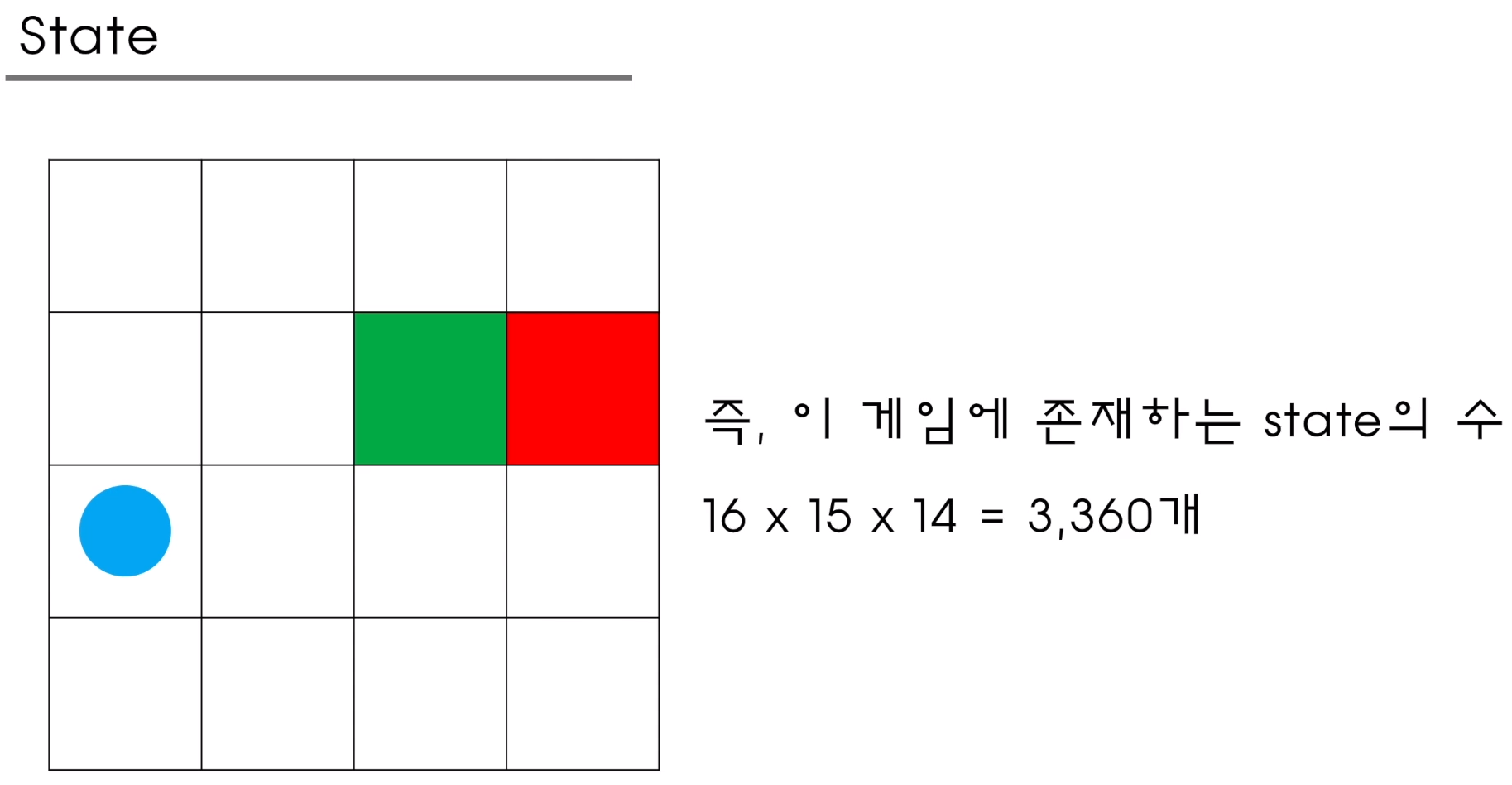
하지만 문제가 있다 예시로 아래와 같다.

학습초반임으로 optimal 한 보상을 원하지않고 0.1 보상만으로 만족하면서 Qtable을 계속 update하게 되는 문제가 생긴다.

일정확률(Epsilon)을 선택하여서 agent가 action 을 랜덤하게 고를수 있도록한다. 게임 후반에 갈수록 Epslion 확률 값을 낮추어주는 방향으로 간다.

유명한 taxi simulation 코드이다.
#!/usr/bin/env python
import numpy as np
import random
import gym
env = gym.make("Taxi-v3")
action_size = env.action_space.n
discount_factor = 0.9
learning_rate = 0.1
run_step = 5000000
test_step = 20
print_episode = 100
epsilon_init = 1.0
epsilon_min = 0.1
train_mode = True
class Q_Agent():
def __init__(self):
self.Q_table = {}
self.epsilon = epsilon_init
def init_Q_table(self,state):
if state not in self.Q_table.keys():
self.Q_table[state] = np.zeros(action_size)
def get_action(self,state):
if self.epsilon > np.random.rand():
return np.random.randint(0,action_size)
else:
self.init_Q_table(state)
predict = np.argmax(self.Q_table[state])
return predict
def train_model(self,state,action,reward,next_state,done):
self.init_Q_table(state)
self.init_Q_table(next_state)
target = reward + discount_factor * np.max(self.Q_table[next_state])
Q_val = self.Q_table[state][action]
if done:
self.Q_table[state][action] = reward
else:
self.Q_table[state][action] = (1-learning_rate) * Q_val + learning_rate * target
if __name__ == '__main__':
agent = Q_Agent()
step =0
episode = 0
reward_list = []
while step < run_step + test_step:
state = str(env.reset())
episode_rewards = 0
done = False
while not done:
if step >= run_step:
train_mode = False
env.render()
action = agent.get_action(state)
next_state, reward, done, _ = env.step(action)
next_state = str(next_state)
episode_rewards += reward
if train_mode:
if agent.epsilon > epsilon_min:
agent.epsilon -= 1.0 / run_step
agent.train_model(state,action,reward,next_state,done)
else:
agent.epsilon = 0.0
state = next_state
step += 1
reward_list.append(episode_rewards)
episode += 1
if episode != 0 and episode % print_episode == 0:
print("Step: {} / Episode: {} / Epsilon: {:.3f} / Mean Rewards: {:.3f}".format(step, episode, agent.epsilon, np.mean(reward_list)))
reward_list = []
env.close()5백만번 훈련(step) 을 시키고
20번 정도 env 를 print 해보았다.
'자율주행 > Deep Q Network' 카테고리의 다른 글
| DQN Upgrade (0) | 2021.02.25 |
|---|---|
| DQN(Deep Q Network) (0) | 2021.02.24 |
| ANN ,CNN -> ㅡMNIST 분석 (0) | 2021.02.22 |