콜레이션 이란
- 문자를 비교하거나 정렬할 때 사용되는 규칙이다.
- 문자집합(Character Set)에 종속적
- 문자와 코드값(코드 포인트)의 조합이 정의돼있는 것이 문자집합이다
- e.g) A=U+0041, B=U+0042
- MySQL에서 모든 문자열 타입 컬럼은 독립적인 문자집합과 콜레이션을 가질 수 있다.
- 사용자가 특별히 지정하지 않은 경우 , 서버에 설정된 문자집합의 디폴트 콜레이션으로 자동 설정된다.
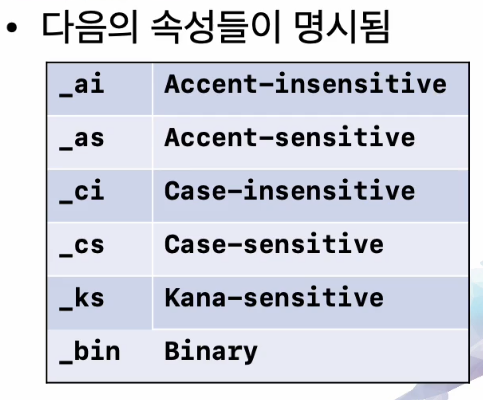
MySQL 에서의 콜레이션 네이밍 컨벤션
문자집합 _ 언어종속 _ UCA버전 _ 민감도
문자집합 = utf8mb4, utf8mb3, latin1, euckr 등등 (해당 콜레이션이 속한 문자집합을 의미함)
언어종속 = 특정언어에 대해 해당 언어에서 정의한 정렬 순서에 의해 정렬 및 비교를 수행한다.
(다른 언어들에는 적용되지 않음)
locale code(e.g. "tr") 또는 language(e.g. "turkish")로 표시된다.
utf8bm4_tr_0900_ai_ci
UCA 버전 =

전부 유니코드 기반 문자집합에 속해있는 콜레이션들로 콜레이션 별로 UCA 버전이 표시되는 형태가 조금 다르다.
general은 UCA기반이아니고 mysql에서 비교, 성능 향상 등을 위해 자체적으로 커스텀한 규칙이 적용된 콜레이션이다.
민감도 =
cs,ks 일본어 쓸때 히라가나와 가타가나 구분
bin은 binary값으로 비교하고 정렬하는 것을 의미한단
콜레이션 동작방식
- 유니코드 기준
- 데이터 저장
- 코드 포인트 값을 인코딩해서 저장한다.
- 예시) 일반적으로 많이 사용되는 UTF-8 인코딩 방식이다.
- 데이터 저장

"가" 의 경우 U+AC00로 표현이되고 이는 3번째 row에속한다. 첫번쨰 A에 해당 하는 4bit는 EA로 들어가고, B0 에 나머지 6bit가 들어간다.
유니코드 기준 ( 데이터 비교 )
- DUCET(Default Unicode Collation Element Table) 에 정의된 가중치 값을 바탕으로 비교
- 가중치 값은 [Primary . Secondary . Tertiary ] 와 같이 단계적으로 구성된다.
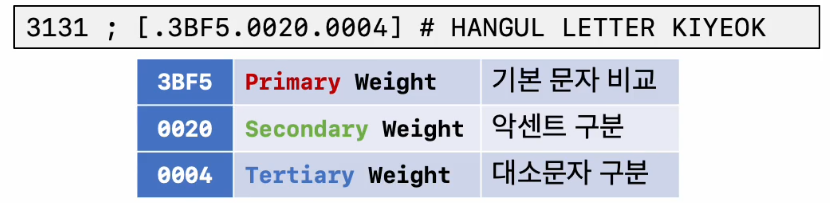
- 콜레이션에 따라 사용되는 가중치 값이 달라짐
- ai_ci 는 1단계 가중치 값(Primary Weight) 까지,
- as_ci 는 2단계 가중치 값(Secondary Weight) 까지,
- as_cs 는 3단계 가중치 값 (Tertiary Weight) 까지 사용한다
- 한글 음절 (e.g."가") 의 경우 분해해서 가중치 값을 조합한 후 비교한다
- WEIGHT_STRING( ) 함수를 통해 문자열의 가중치 값 확인 가능

ai_ci는 1단계 (Primary) 에 해당하는 값이다.
as_cs 는 3단계까지 각 단계를 zero byte 로 연결해서 보여준다.

ㄱ, ㄴ, ㄷ이 지정한 가중치 순서 대로 정렬된 것을 확인 할 수 있다.
콜레이션 설정
- 기본적으로 MySQL 서버에 설정된 문자집합(Character Set)의 디폴트 콜레이션으로 글로벌하게 설정된다.
- 문자집합과 콜레이션 모두 특별히 값을 설정하지 않은 경우, 기본적으로 서버는 utf8mb4 문자집합 & utf8mb4_0900_ai_ci 콜레이션으로 설정된다.
- character_set_server & collation_server 설정 변수를 통해 원하는 문자집합 및 콜레이션 설정이 가능하다
- 데이터비이스 / 테이블 / 컬럼 단위로 독립적으로도 지정이 가능하다



원래는 기존과 다른 콜레이션으로 where절을 사용하면 index가 활용이 안되지만

함수기반 인덱스를 통해서 인덱스를 정의하면 where 절에서도 사용이 가능하다

primary, unique key 도 콜레이션에 영향을 받는다. 즉 중복 비교를 할때 콜레이션에 따라 같은 값이라 해도 중복으로 판단될 수도 안될 수도 있다.
ai_ci였을 경우에는 대소문자를 구분함으로 데이터 저장이 가능했을 것이다.
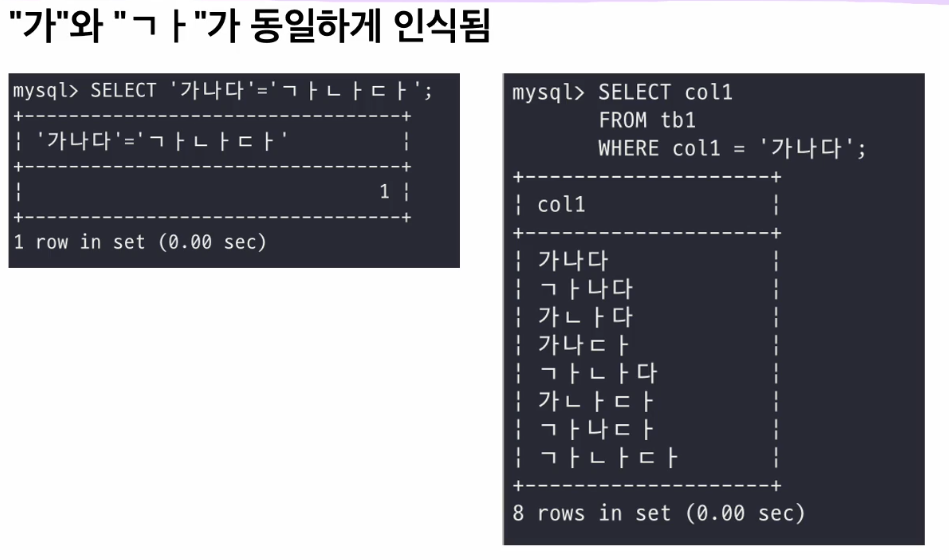
기본 콜레이션인 (utf8mb4_0900_ai_ci)는 오른쪽처럼 다양한 형식들이 다 같은것으로 인식되는 문제가 있다.


DUCET에서는 초중종성 , 문자 별로 다르게 비교한다. 왼쪽은 한글"가" 로 인식해서 초,중,종 성으로 나눠서 인식한것이고 오른쪽은 각각 "ㄱ" "ㅏ" 다른 문자로 인식해서 다른 값이 나온것이다.
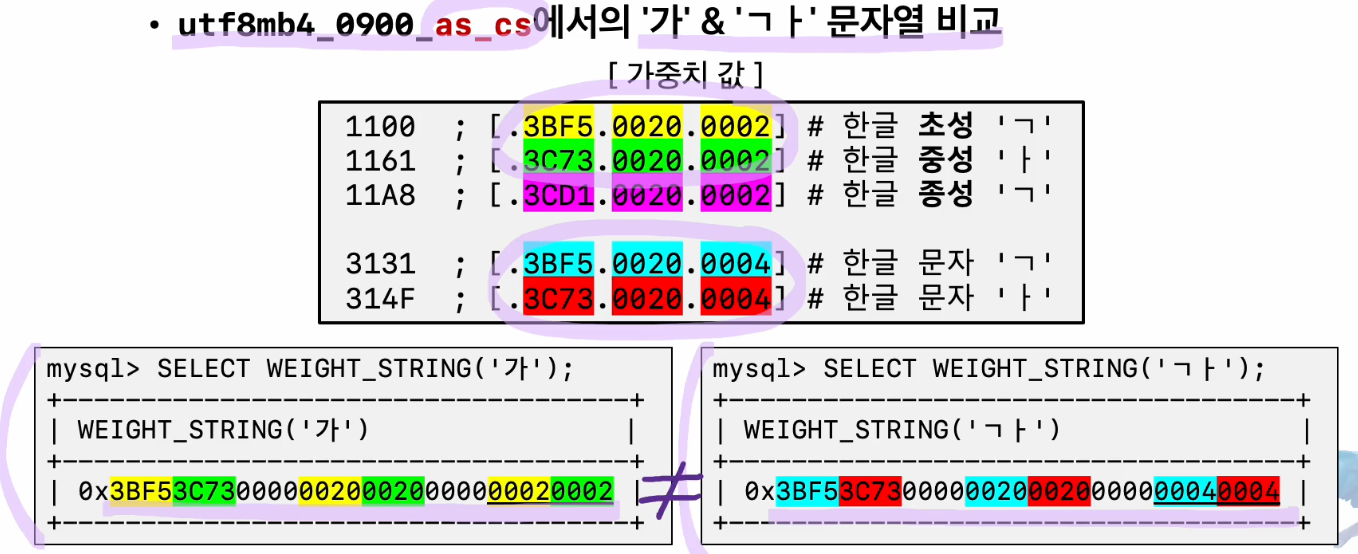
as_cs에서 결과 값 비교이다.

기본 콜레이션 으로 한글을 비교하면 문제가 있을 수 있으니 , where 절에서 위와 같이 비교 조건을 추가해서 사용하면 좋겠다

대소문자 구분을 위한 콜레이션 선정
- 기본 콜레이션 (utf8mb4_0900_ai_ci)는 대소문자를 구분하지 않는다
- utf8mb4 문자집합에 속한 콜레이션 중 대소문자를 구분하는 콜레이션
- utf8mb4_bin
- utf8mb4_0900_bin
- utf8mb4_0900_as_cs


'Database > Real MySQL Season1 ,2' 카테고리의 다른 글
| 15) 풀스캔 쿼리 패턴 및 튜닝 (0) | 2024.10.22 |
|---|---|
| 14) UUID 사용 주의사항 (0) | 2024.10.10 |
| 11) Prepared Statement , 12) SQL 문장의 가독성 향상 (0) | 2024.10.07 |
| 9) Error Handling , 10) Left Join 주의사항 및 튜닝 (0) | 2024.10.03 |
| 8) Generated 컬럼 및 함수 기반 인덱스 (0) | 2024.09.25 |