Deterministic
동일 상태와 동일 입력으로 호출 -> 동일한 결과 반환
그렇지 않은 경우 -> not deterministic

func1 , func2 를 where 조건으로 하고 각각 몇번 호출이 되었는지 세보았다.

각 함수는 사용자 정의 variable에 +1을해서 자기자신이 몇번 호출 되었는지 알 수 있게해주는 함수이다.

explain 결과를 보면 deterministic 은 primary key index를 통해서 1개의 row만 본것을 알 수 있다.
실제 쿼리도 optimize되어서 where true로 변경되었다. 하지만 결과는 3회 호출인데 이는 실제 실행계획말고도
optimziation check, evaluate constants , process filters 등 여러 다른 query execution phases에서 호출이 되어서 그렇다.
반면 not-deterministic은 full scan을 실행하고 where절도 그대로 남아있는것을 확인 할 수 있다. 매 호출마다 변경됨을 가정하였으니까 caching을 제대로 하지 못했을 것이다.
Not Deterministic 함수의 결과는 비확정적이다.
- 매번 호출시점마다 결과가 달라질 수 있다
- 비교 기준 값이 상수가 아니고 변수이다
- 매번 레코드를 읽은 후, wherer 절을 평가할 때마다 결과가 달라질수 있다
- 인덱스에서 특정 값을 검색할 수 없다, 인덱스 최적화가 불가능하다
RAND, UUID ,SYSDATE, NOW 등등 들은 NOT DETERMINISTIC 이다.
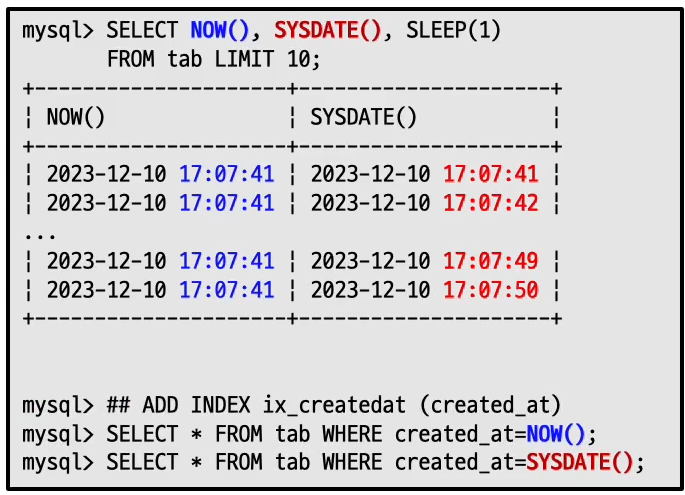
now는 마치 deterministic처럼 반환한다. 하나의 쿼리안에서는 시작된 시간을 return하게 된다.

기본이 Not Deterministic으로 인식된다.
CREATE DEFINER=`user@host` PROCEDURE my_procedure() ...
definer에 user privileges , permissions들을 명시해놓는 영역이다.
아무것도 안쓰면 default로 이 function, procedure를 만든사람으로 정해진다.
sql security invoker는 the privileges of the user who invokes (calls) the procedure are checked.
Lateral Derived Table
- Derived Table (파생 테이블)은 쿼리의 from 절에서 서브쿼리를 통해 생성되는 임시 테이블을 의미한다.
- 일반적으로 derived table 은 선생테이블의 컬럼을 참조할 수 없으나, lateral derived table은 참조 가능하다
- 정의된 dervied table 앞부분에 lateral 키워들르 추가해서 사용한다
- 참조한 값을 바탕으로 동적으로 결과를 생성한다.

lateral 로 join이 실행되는 경우 일반적으로 sub query where 절에 join조건이 사용된다.
employee table의 emp_no에 대한 참조가 잘 이뤄진것을 확인 할 수 있다.
실행계획은 먼저 employees table의 전체 record를 읽으면서 각 record의 emp_no를 바탕으로 sales table의 전체 판매건수와 판매금액을 조회한뒤에 해당 정보들을 포함한 결과 집합을 반환한다.
sales table의 경우 외부 테이블인 employees에 의존적임으로 select_type이 Dependent dervied이다.
예제1)
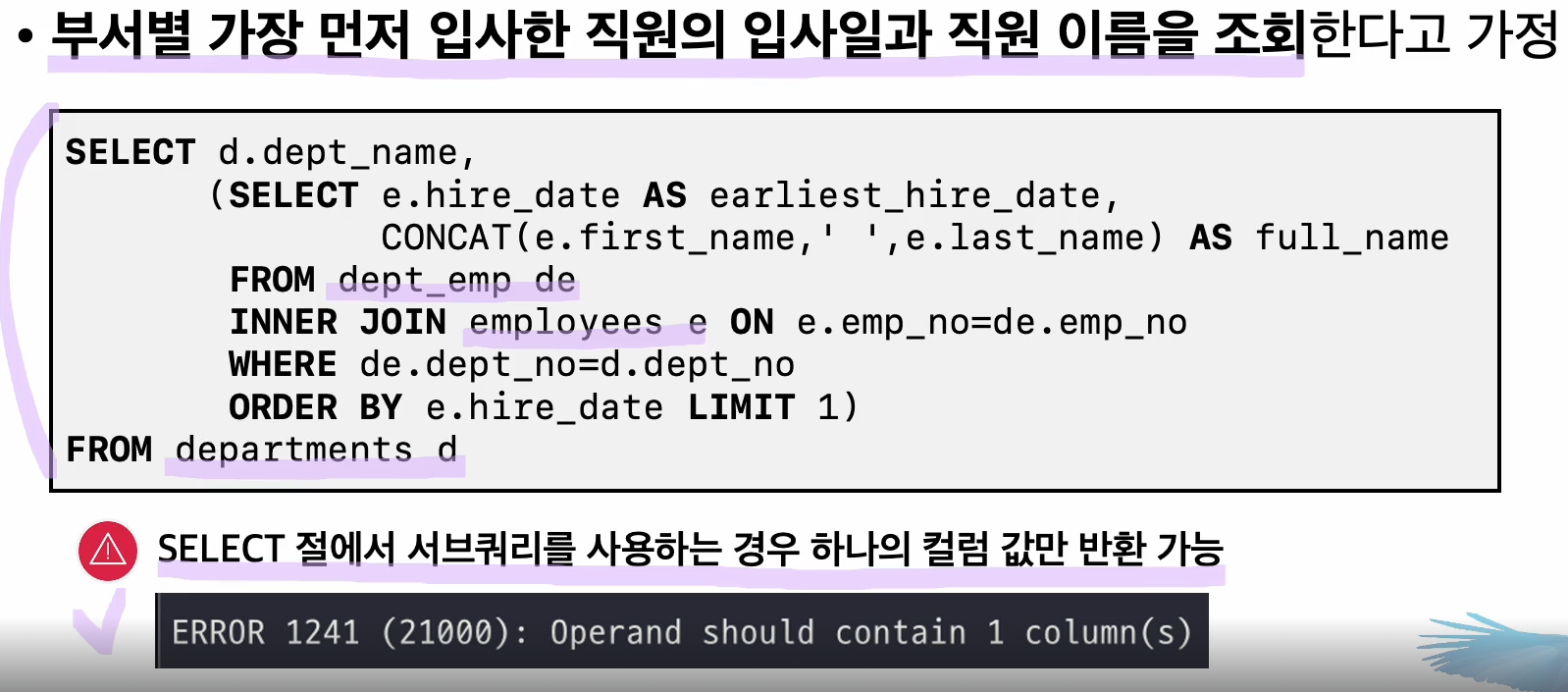
select 에서 subquery를 활용하는 경우 1개의 column만 반환해야 하는데 위예시에서는 hier_date, concat(name) 을 반환하려고 하고있어서 에러가 난것이다.

그래서 2개의 서브쿼리로 나누어서 실행할 수 있지만 이는 동일한테이블의 조인및 조회가 이뤄짐으로 비효율적이다.

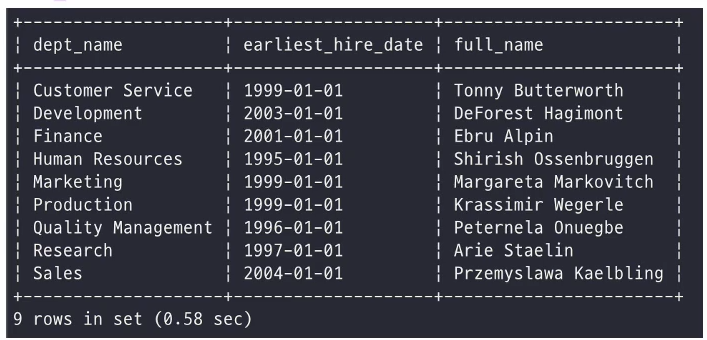
lateral 키워드를 통해서 select 안에서 subquery를 쓰는게 아니라 아예 별도의 derived table을 만들고 외부 table인 department를 access해서 원하는 결과 값을 얻어 올 수 있다.
예제2)

이렇게 연산식을 중복해서 작성한 이유는 select 절에서 계산된 각각의 열값은 동일한 select절 내에 다른 열에서 참조를 할수 없기 때문이다.

순서는 맞아야한다. lateral 로 profit을 먼저 계산하고 정의 했기 때문에 사용할 수 있는 것이다.
예제3)


연속적인 데이터 분석작업의 예시이다. (이전것이 있어야 다음것을 알아내는)

첫번째 box는 2024 1월에 가입한 유저목록을 추출하고 2번째 box에서는 유저별로 처음 결제한 시점 정보를 추출한다.
이 2개의 정보를 user id, 와 결제 시점, 가입한지 7일이 지났는지를 바탕으로 join on절에 명시한다.
2번째 derived table이 비효율적인데 user_events table에서 결제에 해당하는 전체의 데이터들에대한 group by를 수행하기 떄문이다. 즉 분석 대상이 아닌 1월에 가입한 사용자들말고도 다른애들까지 포함이 되기 때문이다.
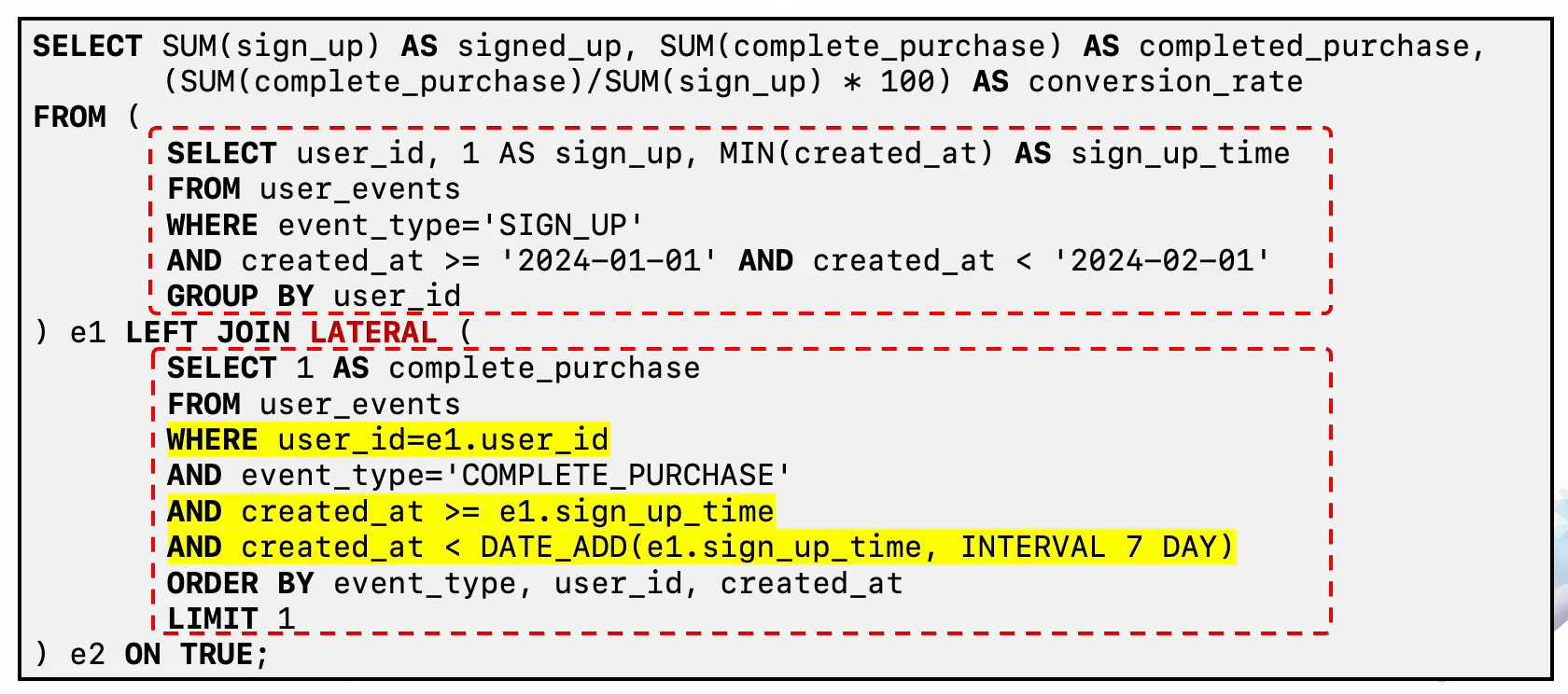
첫번째 table은 동일하고 2번째 table은 lateral 키워드 덕분에 선행테이블에서 가져온user_id를 기반으로 훨씬더 적은 조회를 하게 된다.

조건이 세분화되고 과정이 더 길어지면 성능차이가 더 심할 것이다.
예제4)

뉴스 카테고리 정보가 저장되는 categories , 뉴스기사 정보가 저장되는 articles
category_id, views 로 되어있는 index가 존재한다.


from 절에 subquery로 derived table이 정의되어 있다.
subquery에서는 categories , articels를 join한 후 window함수를 통해 각 데이터에 대해 카테고리 별로 조회수가 많은 순서대로 순위를 매긴 정보를 반환한다. 이후 외부쿼리에서 상위 3개만 반환되도록 필터링 하고 있다.
실행계획에서 article table을 먼저 읽으면서 내부적으로 정렬 작업을 수행하고 이후 category 테이블과 조인한것을 알 수 있다. article 전체를 읽기 때문에 비효율적이다.

categories 와 drived table과 inner join을 수행한다.
실행계획은 categories table을 먼저 읽고 각 데이터별로 articles table을 조회하는데 category_id, views 로 되어있는 index를 활용해서 정렬기준에 따라 3건의 데이터만 읽고 반환하게 된다.
'Database > Real MySQL Season1 ,2' 카테고리의 다른 글
| 9) Error Handling , 10) Left Join 주의사항 및 튜닝 (0) | 2024.10.03 |
|---|---|
| 8) Generated 컬럼 및 함수 기반 인덱스 (0) | 2024.09.25 |
| 7) select for update (0) | 2024.09.24 |
| 3) COUNT(*) & COUNT(DISTINCT) 튜닝 4) 페이징 쿼리 작성 (0) | 2024.09.19 |
| 1) CHAR vs VARCHAR 2) VARCHAR vs TEXT (0) | 2024.09.12 |