멀티노드 카프카 클러스터

- 분산 시스템으로서 카프카의 성능과 가용성을 함께 향상 시킬 수 있도록 구성
- 스케일 아웃 기반으로 노드 증설을 통해 카프카의 메시지 전송과 읽기 성능을 거의 선형적으로 증가 시킬 수 있음
- 데이터 복제를 통해서 분산 시스템 기반에서 카프카의 최적 가용성을 보장
멀티브로커 설치하기
...
broker.id=3
...
listeners=PLAINTEXT://:9094
...
# A comma separated list of directories under which to store log files
log.dirs=/home/tony/kafka/data/kafka-logs-03server.properties를 총 3개 생성한다.
새로운 zookeeper.properties를 만들고 아래처럼 변경해준다.
# the directory where the snapshot is stored.
dataDir=/home/tony/kafka/data/zookeeper_m
Kafka Replication
- 카프카는 개별 노드의 장애를 대비하여 높은 가용성을 제공한다.
- 카프카 가용성의 핵심은 리플리케이션(Replication , 복제)
- Replication 은 토픽생성시 replication factor 설정값을 통해 구성된다.
- Replication factor가 3이면 원본 파티션과 복제 파티션을 포함하여 모두 3개의 파티션을 가짐을 의미한다.
- Replication factor의 개수는 브로커의 개수보다 클수는 없다.
- Replication의 동작은 토픽내의 개별 파티션들을 대상으로 적용이된다.
- 토픽자체적으로 leader, follower를 적용하는것이 아니고 파티션별로 leader, follower가 존재한다.
- Replication factor의 대상인 파티션들은 1개의 Leader와 N개의 Follower로 구성된다.
- Producer와 Consumer는 Leader파티션을 통해서 쓰기와 읽기를 수행한다
- Kafka2.4부터는 Consumer는 follower에서 read가 가능해진다.
- 파티션의 Replication은 Leader에서 Follow으로만 이뤄진다. 데이터의 방향을 말하는것이다.
- 파티션 리더를 관리하는 브로커는 Producer/Consumer의 읽기/쓰기를 관리함과 동시에 파티션 팔로우를 관리하는 브로커의 Replication도 관리

단일 파티션인 경우에는 leader가 부하를 많이 담당하게 되지만
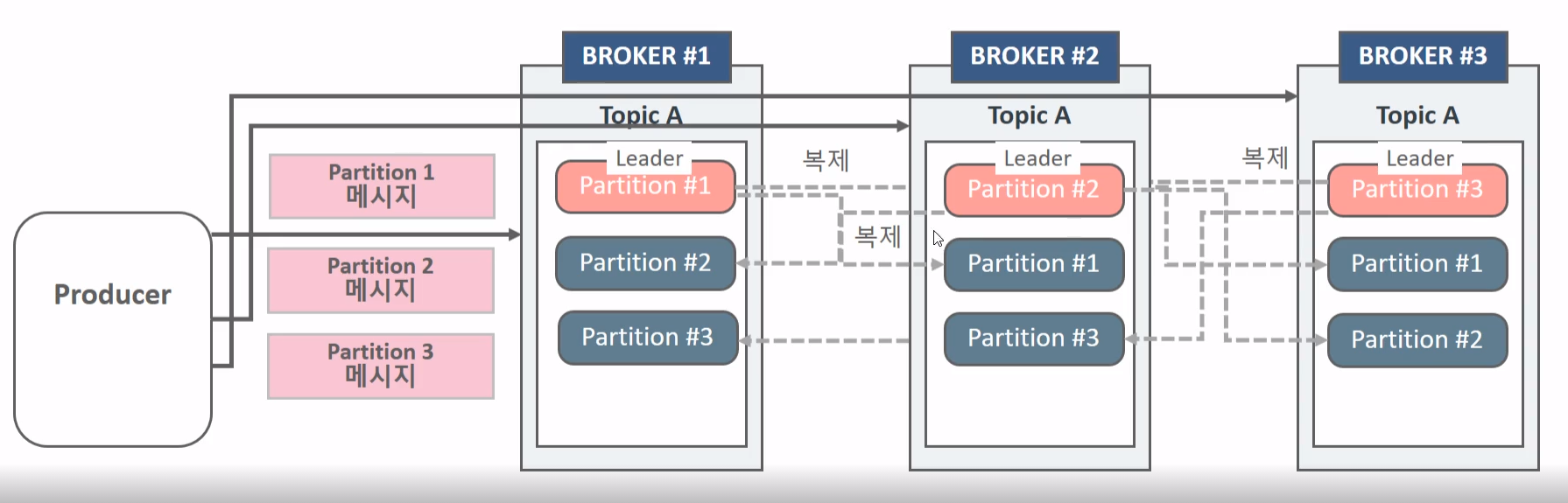
파티셔닝 여러개가 흩뿌려져있는 경우에는 부하를 골고루 담당하게 된다.

partition 별로 복제가 이뤄진다. 나의 경우에는 partition 1으로 다가서 2,3,1 broker에서도 partition1에만 다 복제가 되었다.
~/kafka/confluent-7.6.0/bin » kdl ~/kafka/data/kafka-logs-01/topic-p3r3-0/00000000000000000000.log tony@tony-ubuntu
Dumping /home/tony/kafka/data/kafka-logs-01/topic-p3r3-0/00000000000000000000.log
Log starting offset: 0
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
~/kafka/confluent-7.6.0/bin » kdl ~/kafka/data/kafka-logs-01/topic-p3r3-1/00000000000000000000.log tony@tony-ubuntu
Dumping /home/tony/kafka/data/kafka-logs-01/topic-p3r3-1/00000000000000000000.log
Log starting offset: 0
baseOffset: 0 lastOffset: 1 count: 2 baseSequence: 0 lastSequence: 1 producerId: 1000 producerEpoch: 0 partitionLeaderEpoch: 0 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 0 CreateTime: 1719975664930 size: 87 magic: 2 compresscodec: none crc: 82242102 isvalid: true
| offset: 0 CreateTime: 1719975664105 keySize: -1 valueSize: 8 sequence: 0 headerKeys: [] payload: aaaaaaaa
| offset: 1 CreateTime: 1719975664930 keySize: -1 valueSize: 3 sequence: 1 headerKeys: [] payload: bbb
baseOffset: 2 lastOffset: 2 count: 1 baseSequence: 2 lastSequence: 2 producerId: 1000 producerEpoch: 0 partitionLeaderEpoch: 0 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 87 CreateTime: 1719975666054 size: 72 magic: 2 compresscodec: none crc: 1805459730 isvalid: true
| offset: 2 CreateTime: 1719975666054 keySize: -1 valueSize: 4 sequence: 2 headerKeys: [] payload: cccc
baseOffset: 3 lastOffset: 3 count: 1 baseSequence: 3 lastSequence: 3 producerId: 1000 producerEpoch: 0 partitionLeaderEpoch: 0 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 159 CreateTime: 1719975669398 size: 93 magic: 2 compresscodec: none crc: 3488066742 isvalid: true
| offset: 3 CreateTime: 1719975669398 keySize: -1 valueSize: 25 sequence: 3 headerKeys: [] payload: ddddddddddddddddddddddddd
baseOffset: 4 lastOffset: 4 count: 1 baseSequence: 4 lastSequence: 4 producerId: 1000 producerEpoch: 0 partitionLeaderEpoch: 0 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 252 CreateTime: 1719975672872 size: 99 magic: 2 compresscodec: none crc: 2697668278 isvalid: true
| offset: 4 CreateTime: 1719975672872 keySize: -1 valueSize: 31 sequence: 4 headerKeys: [] payload: eeeeeeeeeeeeeeeeeeeeeeeeeeeeeee
baseOffset: 5 lastOffset: 5 count: 1 baseSequence: 5 lastSequence: 5 producerId: 1000 producerEpoch: 0 partitionLeaderEpoch: 0 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 351 CreateTime: 1719975675005 size: 112 magic: 2 compresscodec: none crc: 1447327596 isvalid: true
| offset: 5 CreateTime: 1719975675005 keySize: -1 valueSize: 44 sequence: 5 headerKeys: [] payload: ffffffffffffffffffffffffffffffffffffffffffff
baseOffset: 6 lastOffset: 6 count: 1 baseSequence: 6 lastSequence: 6 producerId: 1000 producerEpoch: 0 partitionLeaderEpoch: 0 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 463 CreateTime: 1719975677143 size: 110 magic: 2 compresscodec: none crc: 855241325 isvalid: true
| offset: 6 CreateTime: 1719975677143 keySize: -1 valueSize: 42 sequence: 6 headerKeys: [] payload: gggggggggggggggggggggggggggggggggggggggggg
baseOffset: 7 lastOffset: 7 count: 1 baseSequence: 7 lastSequence: 7 producerId: 1000 producerEpoch: 0 partitionLeaderEpoch: 0 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 573 CreateTime: 1719975679144 size: 103 magic: 2 compresscodec: none crc: 3641670149 isvalid: true
| offset: 7 CreateTime: 1719975679144 keySize: -1 valueSize: 35 sequence: 7 headerKeys: [] payload: hhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhh
baseOffset: 8 lastOffset: 8 count: 1 baseSequence: 8 lastSequence: 8 producerId: 1000 producerEpoch: 0 partitionLeaderEpoch: 0 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 676 CreateTime: 1719975680892 size: 96 magic: 2 compresscodec: none crc: 192821625 isvalid: true
| offset: 8 CreateTime: 1719975680892 keySize: -1 valueSize: 28 sequence: 8 headerKeys: [] payload: iiiiiiiiiiiiiiiiiiiiiiiiiiii
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
~/kafka/confluent-7.6.0/bin » kdl ~/kafka/data/kafka-logs-02/topic-p3r3-1/00000000000000000000.log tony@tony-ubuntu
Dumping /home/tony/kafka/data/kafka-logs-02/topic-p3r3-1/00000000000000000000.log
Log starting offset: 0
baseOffset: 0 lastOffset: 1 count: 2 baseSequence: 0 lastSequence: 1 producerId: 1000 producerEpoch: 0 partitionLeaderEpoch: 0 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 0 CreateTime: 1719975664930 size: 87 magic: 2 compresscodec: none crc: 82242102 isvalid: true
| offset: 0 CreateTime: 1719975664105 keySize: -1 valueSize: 8 sequence: 0 headerKeys: [] payload: aaaaaaaa
| offset: 1 CreateTime: 1719975664930 keySize: -1 valueSize: 3 sequence: 1 headerKeys: [] payload: bbb
baseOffset: 2 lastOffset: 2 count: 1 baseSequence: 2 lastSequence: 2 producerId: 1000 producerEpoch: 0 partitionLeaderEpoch: 0 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 87 CreateTime: 1719975666054 size: 72 magic: 2 compresscodec: none crc: 1805459730 isvalid: true
| offset: 2 CreateTime: 1719975666054 keySize: -1 valueSize: 4 sequence: 2 headerKeys: [] payload: cccc
baseOffset: 3 lastOffset: 3 count: 1 baseSequence: 3 lastSequence: 3 producerId: 1000 producerEpoch: 0 partitionLeaderEpoch: 0 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 159 CreateTime: 1719975669398 size: 93 magic: 2 compresscodec: none crc: 3488066742 isvalid: true
| offset: 3 CreateTime: 1719975669398 keySize: -1 valueSize: 25 sequence: 3 headerKeys: [] payload: ddddddddddddddddddddddddd
baseOffset: 4 lastOffset: 4 count: 1 baseSequence: 4 lastSequence: 4 producerId: 1000 producerEpoch: 0 partitionLeaderEpoch: 0 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 252 CreateTime: 1719975672872 size: 99 magic: 2 compresscodec: none crc: 2697668278 isvalid: true
| offset: 4 CreateTime: 1719975672872 keySize: -1 valueSize: 31 sequence: 4 headerKeys: [] payload: eeeeeeeeeeeeeeeeeeeeeeeeeeeeeee
baseOffset: 5 lastOffset: 5 count: 1 baseSequence: 5 lastSequence: 5 producerId: 1000 producerEpoch: 0 partitionLeaderEpoch: 0 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 351 CreateTime: 1719975675005 size: 112 magic: 2 compresscodec: none crc: 1447327596 isvalid: true
| offset: 5 CreateTime: 1719975675005 keySize: -1 valueSize: 44 sequence: 5 headerKeys: [] payload: ffffffffffffffffffffffffffffffffffffffffffff
baseOffset: 6 lastOffset: 6 count: 1 baseSequence: 6 lastSequence: 6 producerId: 1000 producerEpoch: 0 partitionLeaderEpoch: 0 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 463 CreateTime: 1719975677143 size: 110 magic: 2 compresscodec: none crc: 855241325 isvalid: true
| offset: 6 CreateTime: 1719975677143 keySize: -1 valueSize: 42 sequence: 6 headerKeys: [] payload: gggggggggggggggggggggggggggggggggggggggggg
baseOffset: 7 lastOffset: 7 count: 1 baseSequence: 7 lastSequence: 7 producerId: 1000 producerEpoch: 0 partitionLeaderEpoch: 0 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 573 CreateTime: 1719975679144 size: 103 magic: 2 compresscodec: none crc: 3641670149 isvalid: true
| offset: 7 CreateTime: 1719975679144 keySize: -1 valueSize: 35 sequence: 7 headerKeys: [] payload: hhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhh
baseOffset: 8 lastOffset: 8 count: 1 baseSequence: 8 lastSequence: 8 producerId: 1000 producerEpoch: 0 partitionLeaderEpoch: 0 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 676 CreateTime: 1719975680892 size: 96 magic: 2 compresscodec: none crc: 192821625 isvalid: true
| offset: 8 CreateTime: 1719975680892 keySize: -1 valueSize: 28 sequence: 8 headerKeys: [] payload: iiiiiiiiiiiiiiiiiiiiiiiiiiiiProducer의 bootstrap.server 설정

Producers는 bootstrap.servers 에 기술되어 있는 브로커들의 List를 기반으로 접속한다.
저 3개중 metadata를 가져오기위해서 어느 1개만 접속이 되면 된다.
boostrap.servers는 브로커 Listener들의 List이다.
개별 broker들은 토픽 파티션의 Leader와 Follower들의 메타정보를 서로 공유하고
Producer는 초기 접속 시 이 메타 정보를 가져와서 접속하려는 토픽의 파티션이 있는 브로커로 다시 접속한다.
Zookeeper

- 클러스터내 개별 노드의 중요한 상태 정보를 관리하며 분산 시스템에서 리더 노드를 선출하는 역할등을 수행한다.
- 개별 노드간 상태 정보의 동기화를 위한 보잡한 Lock관리 기능 제공
- 간편한 디렉토리 구조 기반의 Z Node를 활용한다.
- Z Node는 개별 노드의 중요 정보를 담고 있다
- 개별 노드들은 Zookeeper의 Z Node를 계속 모니터링 하며 Z Node에 변경 발생시 Watch Event가 트리거 되어 변경 정보가 개별노드들에 통보 된다.
- Zookeeper 자체의 클러스터링 기능이 제공 된다.
- 모든 카프카 브로커는 주기적으로 Zookeeper에 접속하면서 Session Heartbeat를 전송하여 자신의 상태를 보고한다.
- Zookeeper는 zookeeper.session.timeout.ms 이내에 HeartBeat을 받지 못하면 해당 브로커의 노드 정보를 삭제하고 Controller 노드에게 변경사실을 통보한다.
- Controller 노드는 다운된 브로커가 관리하는 파티션들에 대해서 새로운 파티션 Leader Election을 수행한다.
- 만일 다운된 브로커가 Controller이면 모든 노드에게 해당 사실을 통보하고 가장 먼저 접속한 다른 브로커가 Controller가 된다.
zookeeper shell 을 통해서 znode (file system) 로 구성되는 zookeeper commandline admin을 활용할 수 있다.
Leader Election 수행 프로세스
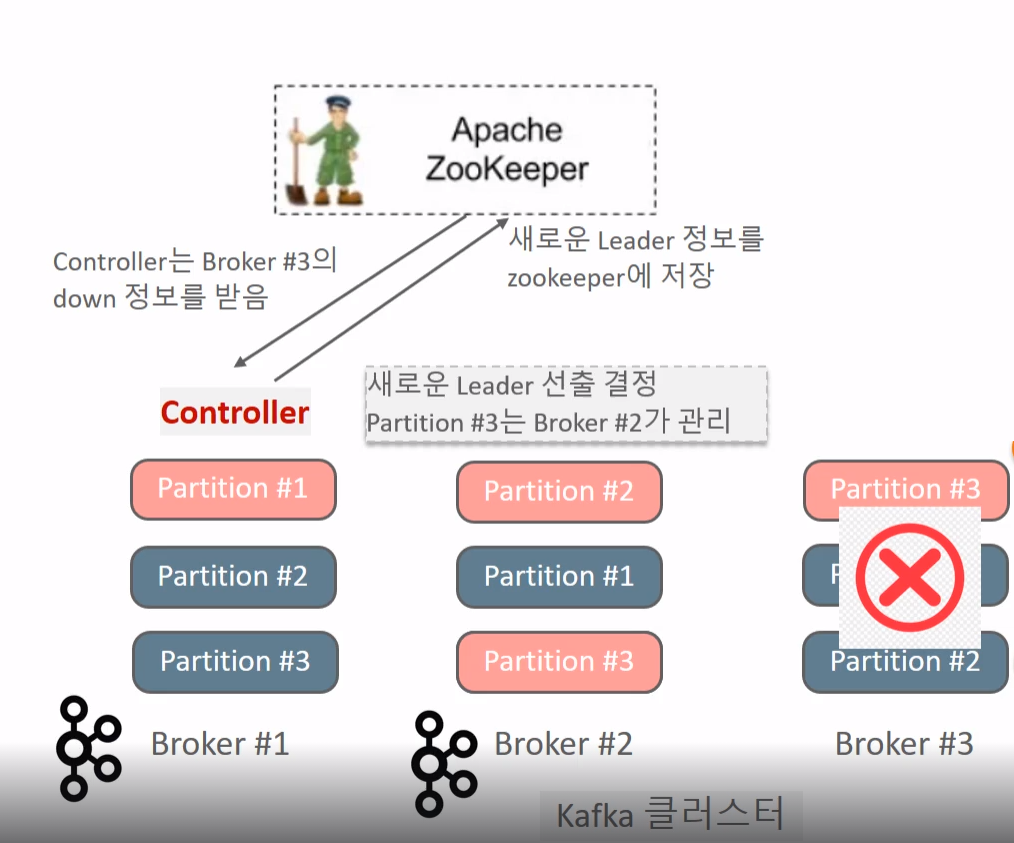
- Broker#3이 Shutdown 되고 Zookeeper는 session기간 동안 Heartbeat이 오지 않으므로 해당 브로커 노드 정보 갱신
- Controller는 Zookeeper를 모니터링 하던 중 Watch Event로 Broker#3에 대한 Down 정보를 받음
- Controller는 다운된 브로커가 관리하던 파티션들에 대해 새로운 Leader/Follower 들을 결정함
- 결정된 새로운 Leader/Follower 정보를 Zookeeper에 저장하고 해당 파티션을 복제하는 모든 브로컫르에게 새로운 Leader/Follower 정보를 전달하고 새로운 Leader로 부터 복제 수행할것을 요청한다
- Controller는 모든 브로커가 가지는 Metadatacache를 새로운 Leader/Follower 정보로 갱신할 것을 요청한다.
In-Sync Replicas
- Follwer들의 누구라도 Leader가 될 수 있지만 , 단 ISR 내에 있는 Follower들만 가능하다
- 일종의 건강한 Follower들을 추려낸다고 생각하면 된다.
- 파티션의 Leader 브로커는 Follower 파티션의 브로커들이 Leader가 될 수 있는지 지속적으로 모니터링 수행하여 ISR을 관리한다.
- Leader 파티션의 메시지를 Follower가 빠르게 복제하지 못하고 뒤쳐질 경우 ISR에서 해당 Follower는 제거되며 Leader가 문제가 생길 때 차기 Leader가 될 수 없다.
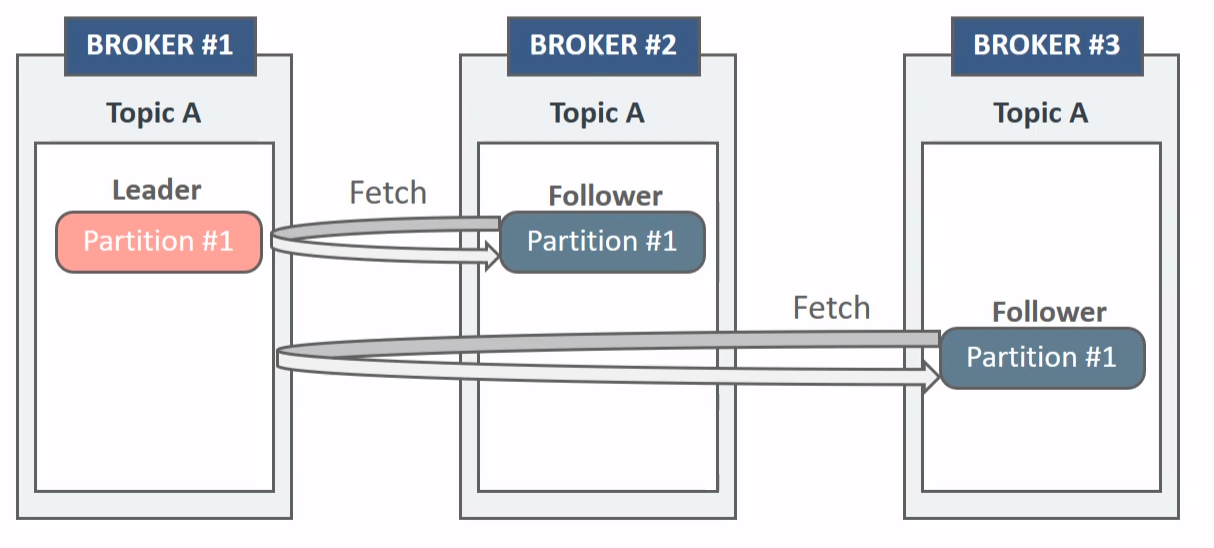
- 브로커가 Zookeeper에 연결되어 있어야한다. zookeeper.session.timeout.ms 로 지정된 기간(기본 6초, 최대 18초) 내에 HeartBeat를 지속적으로 Zookeeper로 보낸다.
- replica.lag.time.max.ms로 지정된 기간 (기본 10초, 최대 30초) 내에 Leader의 메시지를 지속적으로 가져 가야한다.
- Leader 파티션이 있는 브로커는 Followerㄷ르이 제대로 데이터를 가져가는지 모니터링하며서 ISR을 관리한다.
ISR 조건
- Follower는 Leader에게 Fetch요청을 수행한다. Fetch 요청에는 Follower가 다음에 읽을 메시지의 offset 번호를 포함하게 된다.
- Leader는 Follower가 요청한 offset 번호와 현재 Leader partition의 가장 최신 offset 번호를 비교하여 Follower가 얼마나 Leader데이터 복제를 잘 수행하고 있는지 판단한다.
min.insync.replicas (broker의 설정값)
min.insync.replicas 파리미터는 브로커의 설정값으로 Producer가 acks=all로 성공적으로 메시지를 보낼 수 있는 최소한의 ISR 브로커 개수를 의미한다.
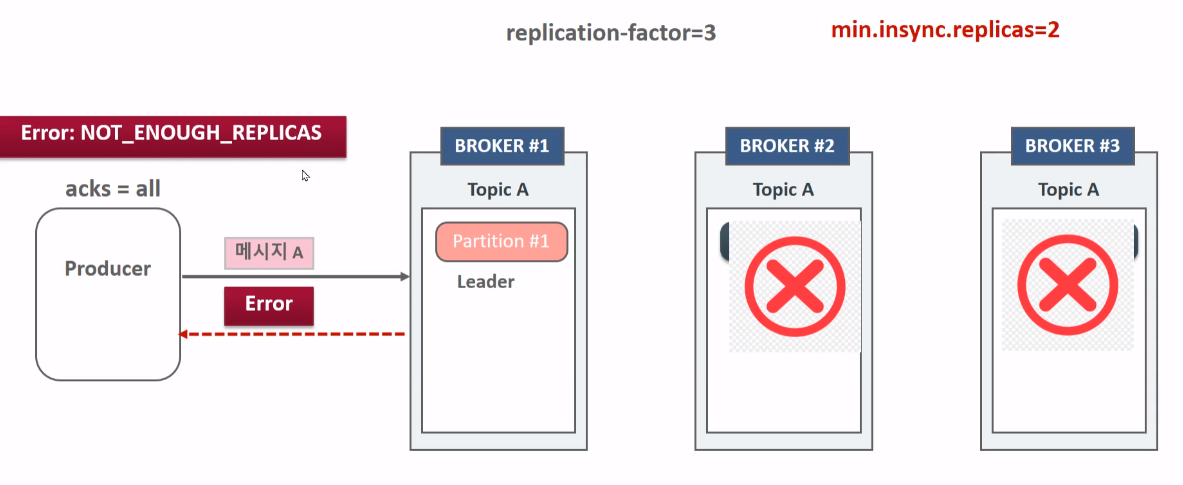
이러한 경우 2를 만족시킬 수 없으니까 에러를 return 하게 된다.
Preferred Leader Election

파티션 별로 최초 할당된 Leader/Follower Broker설정을 Preferred Broker로 그대로 유지한다.
Broker가 shutdown후 재 기동될 때 Preferred Leader Broker를 일정시간 이후에 재 선출하게 된다.
auto.leader.rebalance.enable=true로 설정하고 leader.imbalance.check.interval.seconds (기본 300초)
를 일정시간으로 설정할 수 있다.
broker3 ->2 -> 1순으로 죽이면 여전히 Preferred Broker는 1이다. 그나마 최신 message를 지니고 있을거기 때문이다.
근데 2번만 되살아난다면 leader가 없는 경우가 생기는데 이떄 unclean Leader election을 고려해야 한다.
Unclean Leader Election
기존의 Leader 브로커가 오랜 기간 살아나지 않을 경우 복제가 완료되지 않은 (Out of Sync) Follower Broker가 Leader가 될지 결정해야한다.
이떄 기존의 Leader 브로커가 가진 메시지 손실 여부를 감수하고 복제가 완료되지 않은 Follower Broker가 Leader가 되려면 unclean.leader.election.enable=true로 설정하고 Unclean leader election을 수행해야한다.
'Cloud > kafka-core' 카테고리의 다른 글
| Topic Segment (0) | 2024.07.09 |
|---|---|
| Kafka File Producer App + File Consumer App (0) | 2024.06.30 |
| Kafka Consumer - 03 (0) | 2024.06.18 |
| Kafka Consumer - 02 (0) | 2024.06.04 |
| Kafka Consumer - 01 (0) | 2024.05.16 |