FlowJob - 개념 및 API 소개
1. 기본개념
- Step을 순차적으로만 구성하는 것이 아닌 특정한 상태에 따라 흐름을 전환하도록 구성할 수 있으며 FlowJobBuilder에 의해 생성된다.
- Step이 실패하더라도 Job은 실패로 끝나지 않도록 해야하는 경우
- Step이 성공했을 때 다음에 실행해야할 Step을 구분해서 실행 해야하는 경우
- 특정 Step은 전혀 실행되지 않게 구성 해야하는 경우
Flow 와 Job은 흐름을 구성하는데만 관여하고 실제 비지니스 로직은 Step에서 이루어진다.
내부적으로 SimpleFlow 객체를 포함하고 있으며 Job 실행시 호출한다.

@Bean
public Job batchJob() {
return jobBuilderFactory.get("batchJob")
.start(step1())
.on("COMPLETED").to(step2())
.from(step1())
.on("FAILED").to(step3())
.end()
.build();
}on (어떤 조건이 충족이되면) -> to (Step) 해당 step을 실행해라
from 도 마찬가지로 step1에서 on조건에따라 어떤 step을 실행해라
step1 에서 실패하면 step3를 실행하게 되는데 이때 전체적인 JobExecution은 성공했다 db에 저장이 되게 된다.
일종의 try catch 문 처럼 유연하게 동작을 하게 되는것이다.
FlowJob#doExecute에서 SimpleFlow를 실행시키게 된다. 마치 SimpleJob이 step을 가지고 있는것 과 유사하다.
FlowJob - start() / next()
위의 구성은 Step 을 Flow 별로 분리하여 구서하는 장점은 있지만 Step 중 하나라도 실패할 경우 전체 Job이 실패하는 규칙은 동일하다.
위에서는 on이라는 api를 통해서 catch 역할을 해줘서 실패하더라도 Job전체는 성공이었는데 위 상황은 단순히 절차적으로 Flow를 실행하기 때문에 하나라도 실패하면 Job이 실패하는것이다.
Transition - 배치상태 유형 (BatchStatus / ExitStatus / FlowExecutionStatus)
BatchStatus
- JobExecution 과 StepExecution 의 속성으로 Job과 Step의 종료후 최종결과 상태가 무엇인지 정의 -> 최종 결과 상태
SimpleJob
- 마지막 Step의 BatchStatus 값을 Job의 최종 BatchStatus 값으로 반영
- Step이 실패할 경우 해당 Step이 마지막 Step 이 된다.
FlowJob
- Flow 내 Step 의 ExitStatus값을 FlowExecutionStatus 값으로 저장
- 마지막 Flow 의 FlowExecutionStatus 값을 Job의 최종 BatchStatus 값으로 반영

ExitStatus
- JobExecution 과 StepExecution의 속성으로 Job 과 Step의실행 후 어떤 상태로 종료 되었는지 정의 -> 종료상태
- 기본적으로 ExitStatus 는 BatchStatus와 동일한 값으로 설정된다.
SimpleJob
- 마지막 Step의 ExitStatus 값을 Job의 최종 ExitStatus 값으로 반영
FlowJob
- Flow내 Step 의 ExitStatus 값을 FlowExecutionStauts 값으로 저장
- 마지막 Flow 의 FlowExecutionStatus 값을 Job의 최종 ExitStatus 값으로 반영

FlowExecutionStatus
- FlowExecution의 속성으로 Flow의 실행후 최종 결과 상태가 무엇인지 정의
- Flow 내 Step이 실행되고 나서 ExitStatus 값을 FlowExecutionStatus 값으로 저장
- FlowJob의 배치결과상태에 관여함

public Step step1() {
return stepBuilderFactory.get("step1")
.tasklet((contribution, chunkContext) -> {
System.out.println(">> step1 has executed");
contribution.setExitStatus(ExitStatus.FAILED);
return RepeatStatus.FINISHED;
})
.build();
}step1이 Failed가 되어도 정상적으로 실행은 되었기 때문에 BatchStatus는 Completed 가 db에 저장이되고 ExitStatus만Failed가 된다.
JobExecution은 마지막 StepExceution 의 BatchStuats, ExitStatus를 그대로 반영한다.
Transition - on() / to() / stop() ,fail(), end(), stopAndRestart()
기본개념
Transition
- Flow 내 Step의 조건부 전환(전이) 를 정의함
- Job의 API설정에서 on(String pattern) 메소드를 호출하면 TransitionBuilder가 반환되어
Transition Flow를 구성할 수 있음 - Step의 종료상태(ExitStatus) 가 어떤 pattern 과도 매칭이되지않으면 스프링 배치에서 예외를 발생하고 Job은 실패
- transition 은 구체적인 것 부터 그렇지 않은 순서로 적용된다
API
on
- Step의 실행결과로 돌려받는 종료 상태(ExitStatus) 와 매칭하는 패턴 스키마 , BatchStatus 와 매칭하는것이 아님
- pattern 과 ExitStatus가 매칭이되면 다음으로 실행할 Step을 지정할 수 있다.
- 특수문자는 2가지만 허용
- * = 0 개이상의 모든 문자
- ? = 1개의 문자
to = 다음으로 실행할 단계를 지정
from = 이전 단계에서 정의한 Transition 을 새롭게 추가 정의함
Job을 중단하거나 종료하는 Transition API
- Flow가 실행되면 FlowExecutionStatus 에 상태값이 저장되고 최종적으로 Job의 BatchStatus 와 ExitStatus 에 반영된다.
- Step의 BatchStatus 및 ExitStatus 에는 아무런 영향을 주지 않고 Job의 상태만을 번경한다.
stop
- FlowExecutionStatus 가 stopped 상태로 종료되는 transition
- Job의 BatchStatus 와 ExitStatus 가 stopped 으로 종료됨
fail
- FlowExecutionStatus가 failed 상태로 종료되는 transition
- Job의 BatchStatus 와 ExitStatus 가 failed 으로 종료됨
end
- FlowExecutionStatus가 completed 상태로 종료되는 transition
- Job의 BatchStatus 와 ExitStatus 가 completed 으로 종료됨
- Step의 ExitStatus가 failed 이더라도 job의 batchstuats는 completed 로 종료하도록 가능하며
이때 Job의 재시작은 불가능함
stopAndRestart
- stop과 기본흐름은 동일
- 특정 step 에서 작업을 중단하도록 설정하면 중단 이전의 Step만 completed 로 저장되고 이후의 step은 실행되지 않고 stopped 상태로 job 종료
- job이 다시 실행됐을 때 실행해야할 Step을 restart 인자로 넘기면 이전에 completed 로 저장된 step 은 건너뛰고 중단이후 step 부터 시작한다.
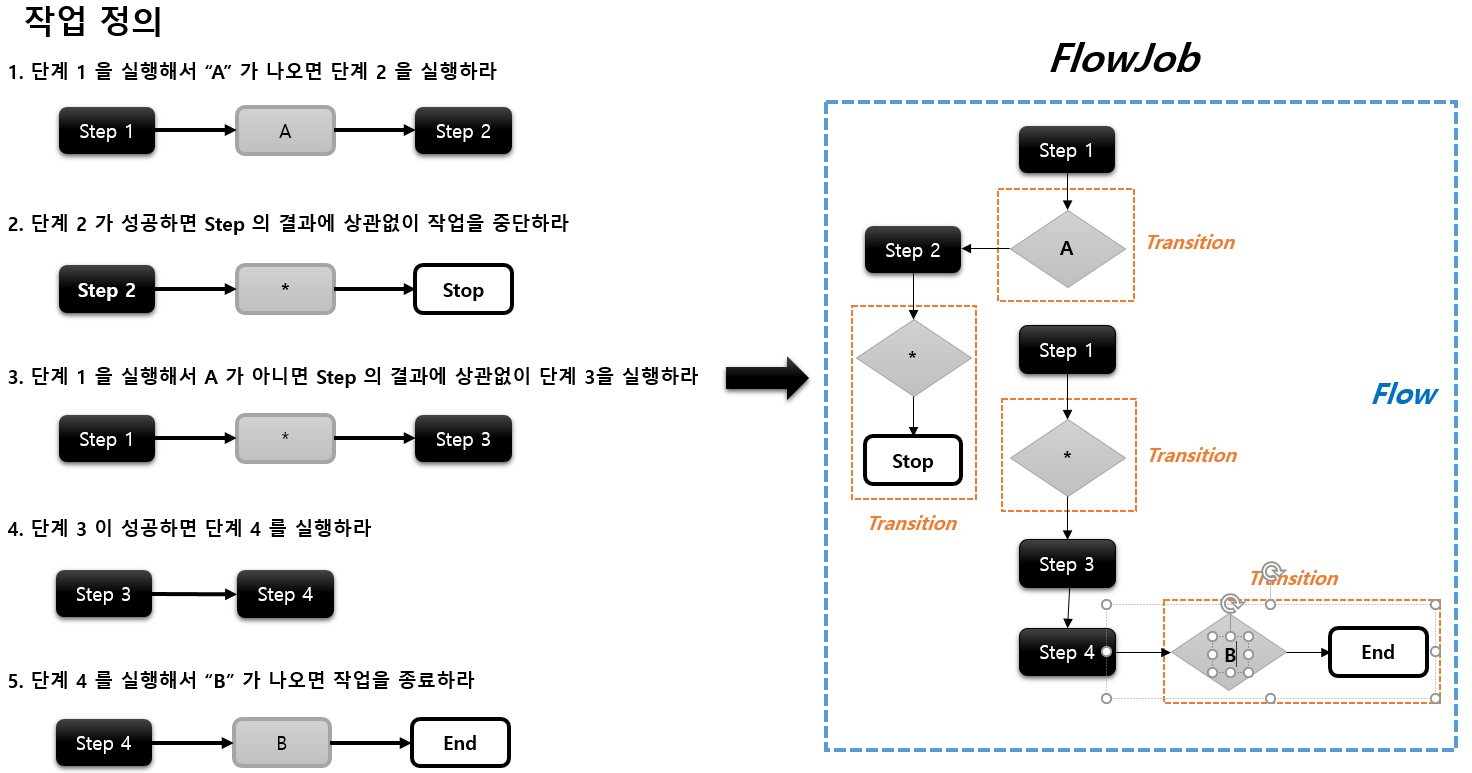
각 작업을 하나의 Flow로 나타낸것이다.
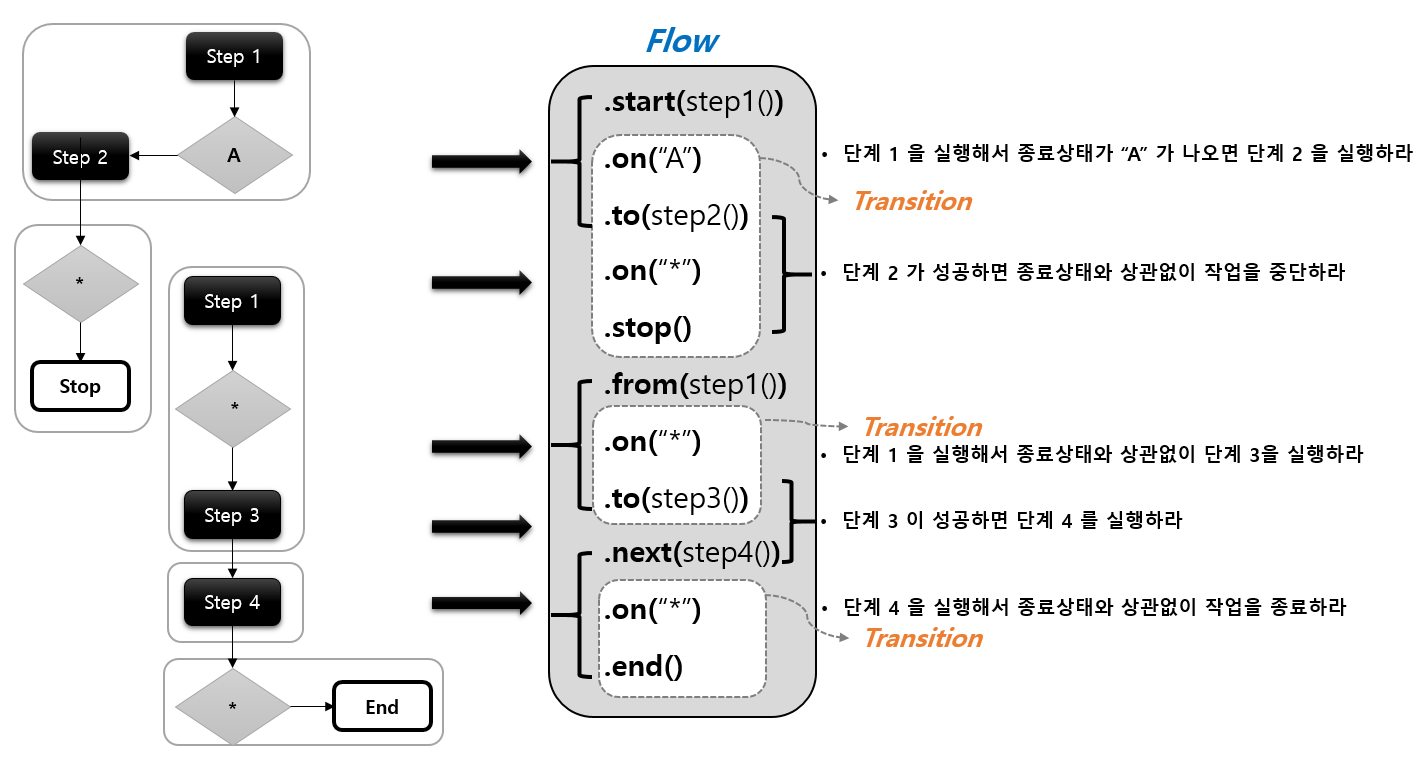
단계 1, 2 가 연결이 되어있고 단계3 4 가 분리되어서 동작하는 것을 확인할 수 있다.
Step1은 제일 처음에 Transition을 이미 정의 했지만 새롭게 Transition을 정의하기위해서 from을 사용한 것이다.

왼쪽에서 job execution의 Stopped는 stop api때문인것이고
오른쪽에서 job execution 이 completed 인것은 비록 step의 마지막이 Failed이지만 이것은 우리가 의도한대로 동작한 것이기 때문에 완료라고 보는것이다.
@Bean
public Job batchJob() {
return this.jobBuilderFactory.get("batchJob")
.start(step1())
.on("FAILED")
.to(step2())
.on("FAILED")
.stop()
.from(step1())
.on("*")
.to(step3())
.next(step4())
.from(step2())
.on("*")
.to(step5())
.end()
.build();
}step1에 Failed하게 된다면 step2를 실행하고 step가 Failed가 아니라 Completed 라면 마지막구문 Transition으로 들어가게 되어 step5를 실행시키게 될 것이다.
사용자 정의 ExitStatus
1. 기본개념
- ExitStatus 에 존재하지 않는 exitCode를 새롭게 정의해서 설정
- StepExecutionListener 의 afterStep 메서드에서 Custom exitCode 생성 후 새로운 ExitStatus 반환
- Step 실행 후 완료 시점에서 현재 exitCode를 사용자 정의 exitCode 로 수정할 수 있음
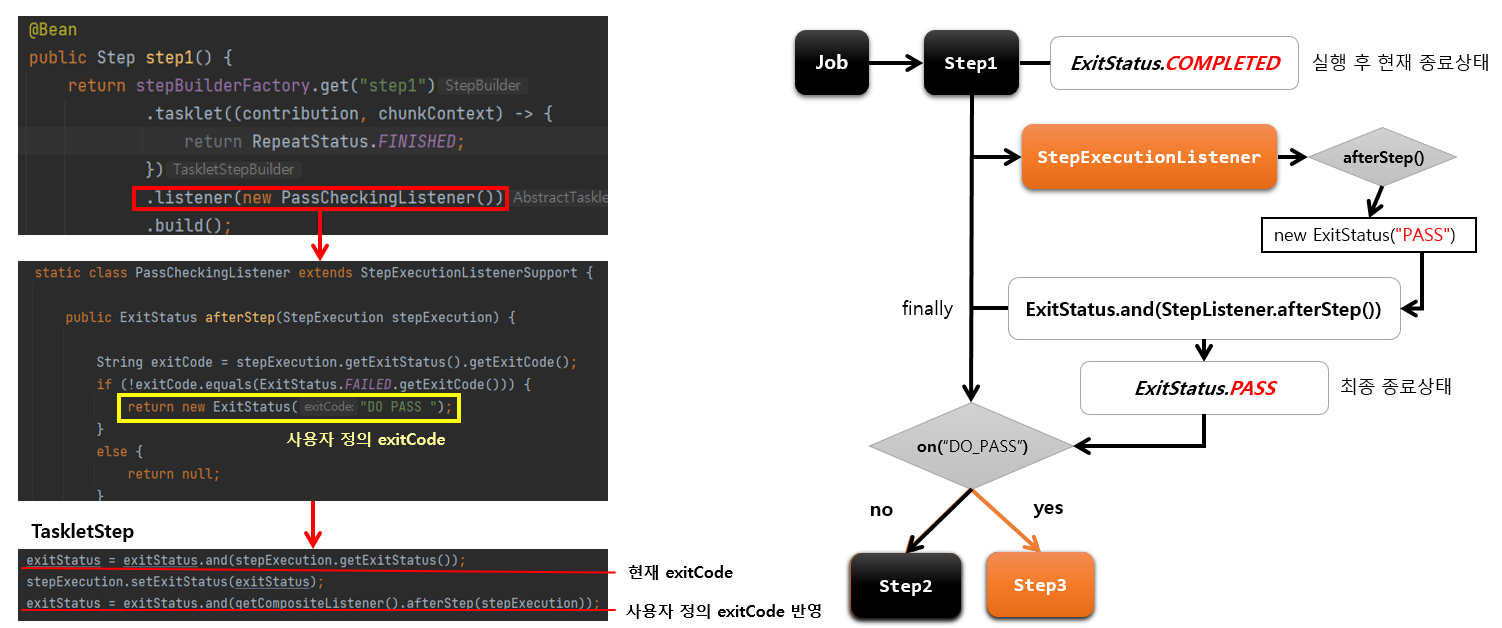
afterStep에 정의한 exitCode로 override되어서 이것을 기준으로 Transition이 분기를 탄다.
@Bean
public Job batchJob() {
return this.jobBuilderFactory.get("batchJob")
.start(step1())
.on("FAILED")
.to(step2())
.on("PASS")
.stop()
.end()
.build();
}job execution은 원래 마지막 step의 batch stauts ,exit stauts를 따라가기 마련인데 현재 해당 코드를 실행하고 db의 job execution table을 보면 Failed라 나온다.
뒤에서 추가적으로 배우지만 현재 "PASS" 인 상태만 정의하고 그 외의 상태는 정의가 되어있지 않아 PASS 분기를 안탈시 Failed가 뜬것이다.
JOB 상태값 관련 질문 - 인프런 | 질문 & 답변
안녕하세요 상태값 관련해서 질문이 있습니다. 18:07초에서 step2()가 COMPLETED 되어도 on에는 PASS만 정의되어 있기 때문에 step2의 ExitStatus가 PASS가 아니라면 Job의 BatchStatus와 ExitStatus는 FAILED로 된다고
www.inflearn.com
PASS 상태만 정의하면 FlowBuilder#addDanglingEndStates 에서 Failed Transition을 추가해줘서 Failed가 job execution state가 된다.
tos 는 to 에 해당하는 값들을 저장하게 된다. 위 예시에서는 to(step2()) , stop()이 해당된다. 그냥 on 다음에 나오는 녀석들인듯하다.
tos에 값이 있어야 Failed, Completed를 추가해주는 (보통 Failed가 기본으로 추가되면 Completed는 추가가되지 않음 , 로직상) 로직이 동작하게 된다.
JobExecutionDecider
1.기본개념
- ExitStatus를 조작하거나 StepExecutionListener 를 등록할 필요 없이 Transition 처리를 위한 전용 클래스
- Step 과 Transition 역할을 명확히 분리해서 설정할 수 있음
- Step 의 ExitStatus 가 아닌 JobExecutionDecider 의 FlowExecutionStatus 상태값을 새롭게 설정해서 반환함
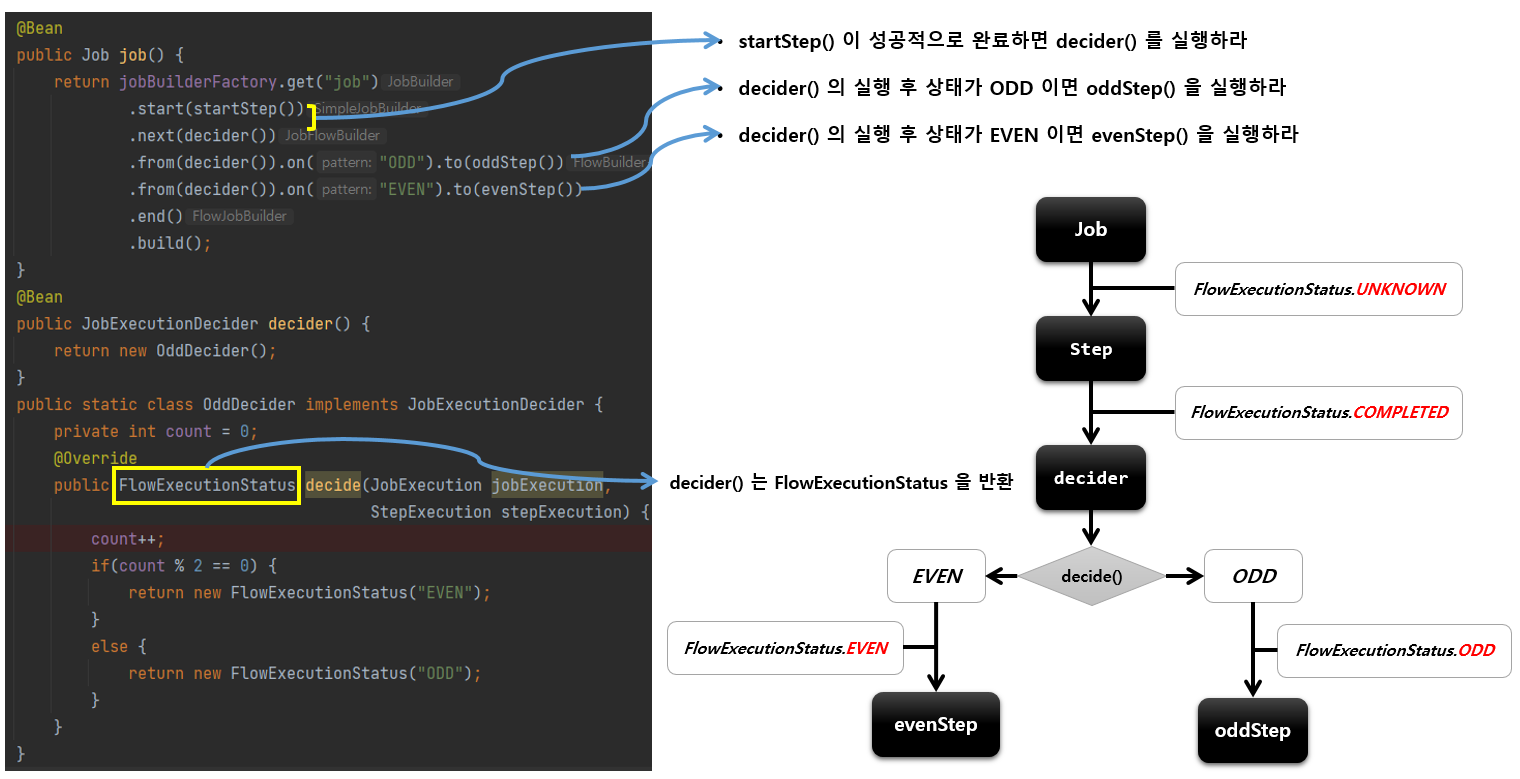
위 에시에서는 StepExecutionListener를 등록해서 PASS 가 return 되는 경우에 관련하여 분기로직을 작성하였지만 그럴 필요없이 추가적인 분기를 step ,flow의 상태와 관련없이 독립적으로 작성할 수 있도록 도와준다.
next 는 Step 는 메소드랑 , JobExecutionDecider를 받는 메소드 2개가 존재한다.
DecisionState 에서 CustomDecider인 OddDecider#decide를 호출하게 된다.
FlowJob 아키텍처
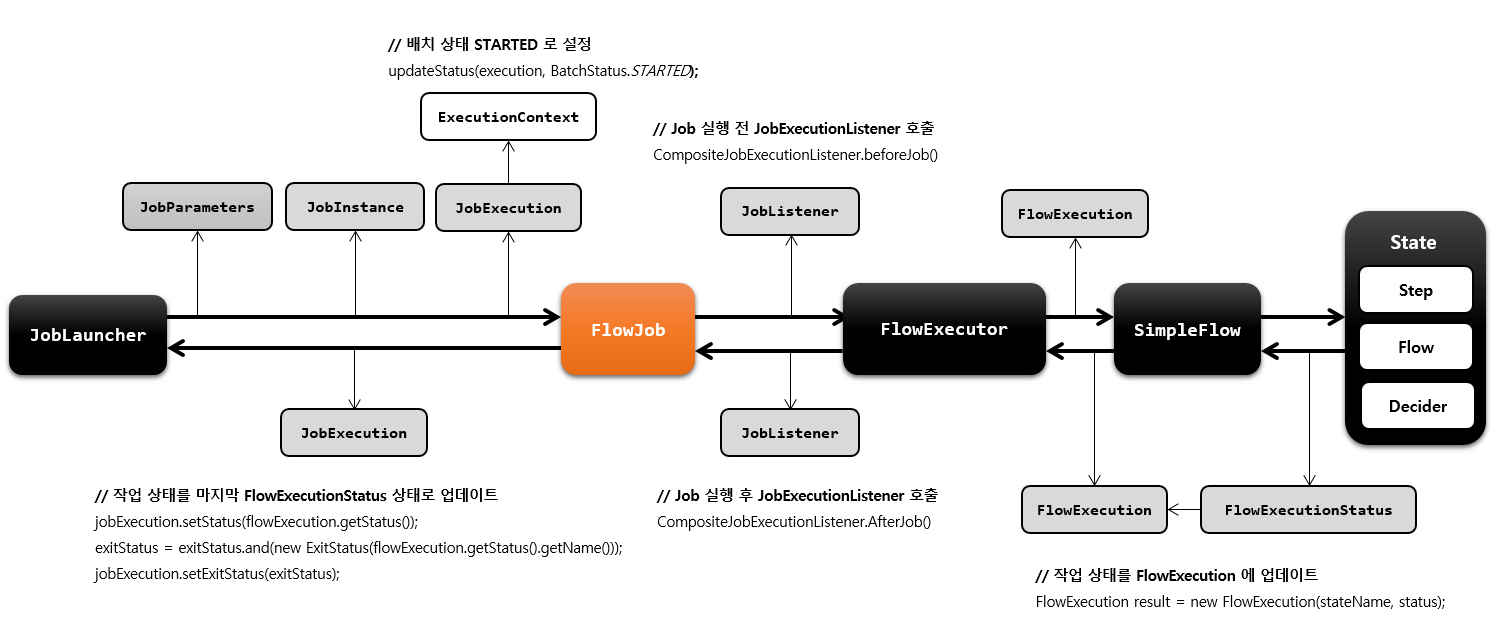
SimpleFlow에서 State는 위에서 api로 사용했던 것들을 의미한다. Step,Flow,Decider
BatchStatus, ExitStatus 는 Job, Step 이 2개다 동시에 가지고있는 Status이고 FlowJob은 FlowExecutionStatus를 가진다. 마지막 FlowExecutionStatus를 BatchStatus, ExitStatus에 반영하게 된다.
햇갈릴 수있다.
FlowJob이 SimpleFlow를 가지고 있다. 이 SimpleFlow는 @Bean으로 정의했던 Flow를 가지고 있다.
이 SimpleFlow 안에 또 SimpleFlow가 존재하고 이번에는 @Bean으로 정의했던 Flow가 내부적으로 step0,1로 구성된것을 그대로 step으로 들고 있다.
SimpleFlow- 개념 및 API 소개
1. 기본개념
- 스프링 배치에서 제공하는 Flow의 구현체로서 각 요소(Step, Flow , JobExecutionDecider) 들을 담고 있는 State 를 실행시키는 도메인 객체
- FlowBuilder를 사용해서 생성하며 Transition 과 조합하여 여러 개의 Flow및 중첩 Flow를 만들어 Job을 구성할 수 있다.
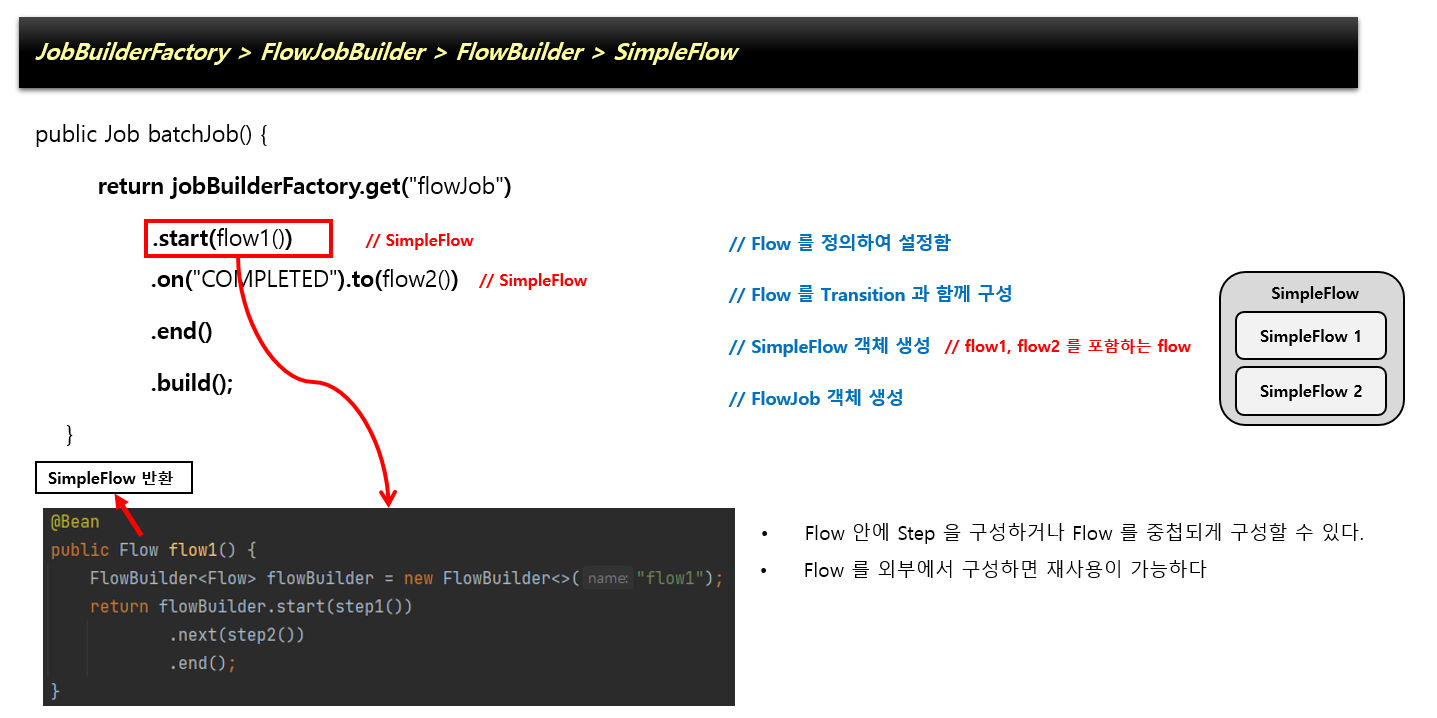
위에서 언급한것처럼 SimpleFlow 안에 SimpleFlow들이 존재한다.
최상단 SimpleFlow가 우리가 정의한 내부 SimpleFlow들을 가지고 있고 각 내부 SimpleFlow는 State#handle을 통해 실제 step을 실행시키게 된다.
State는 Step, JobExecutionDecider , Flow 중 하나이다.

Flow2는 FLow3를 내부적으로 가지고 있다. Flow안에 Flow를 집어넣을 수 있다.
SimpleFlow 아키텍처
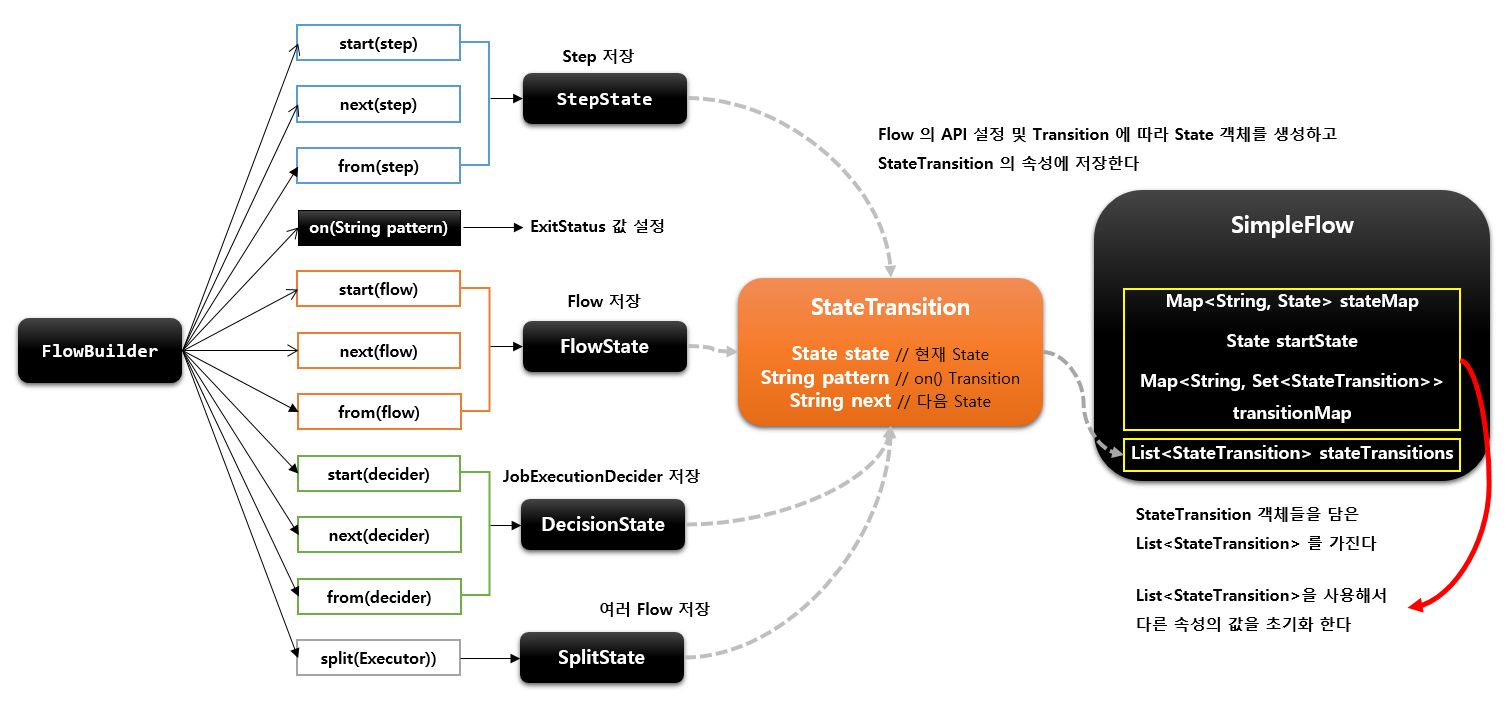
StateTransition은 현재 state -> 다음 state 로 갈 수 있는 이정표 역할을 하게되고
그것을 SimpleFlow가 List로 지니고 있으면서 어디로 가야할지 결정하게 된다.
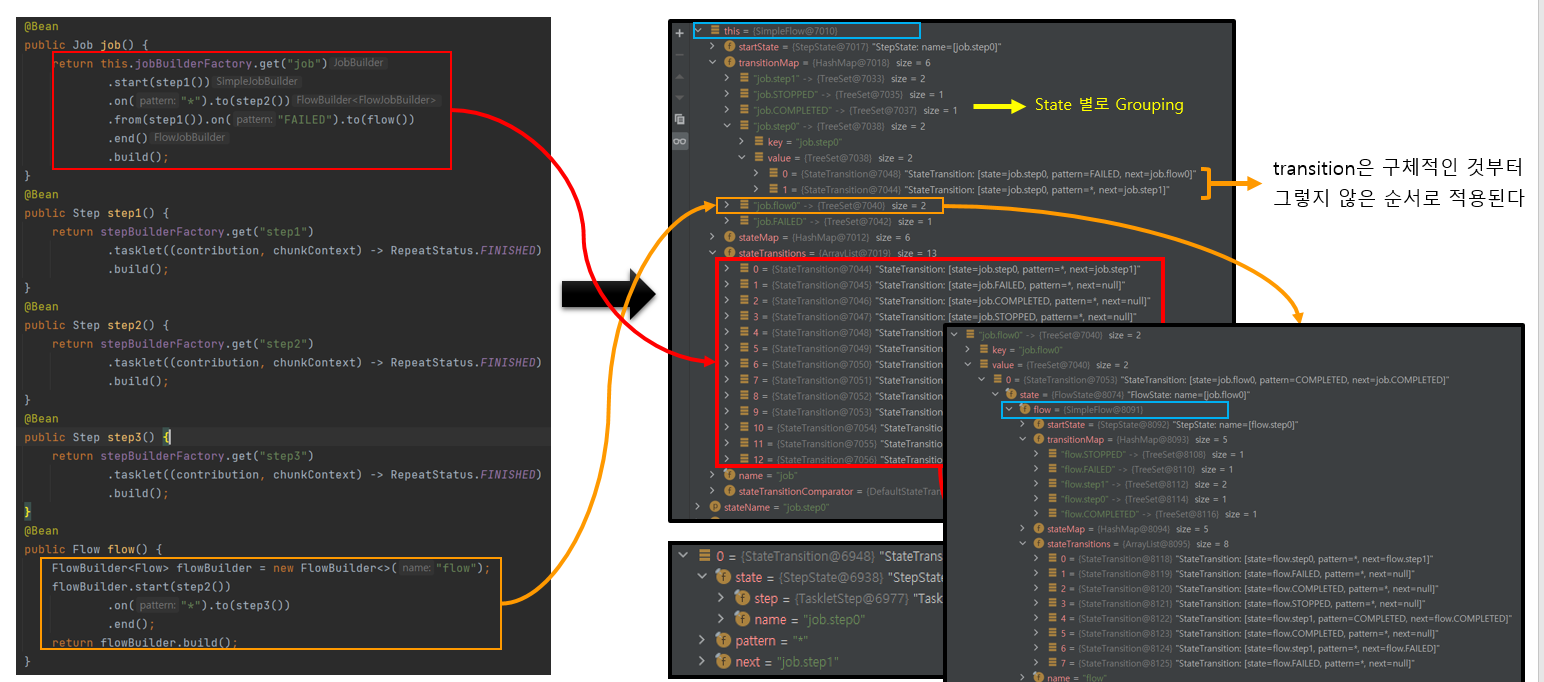
오른쪽에 job.step1 이 의미하는것은 1은 index다 즉 step2를 의미하는것이다.
job.step0가 step1을 의미하는 것이고 실제로 step1은 Failed일 경우 flow0로 가고 그외에 나머지는 *는 step2로 가게 되어있다.
transition은 구체적인 Failed가 먼저적용이 되고 (필터링이되고) 들 구체적인 * 가 적용되어 나머지를 처리하는 역할을 하게 된다.
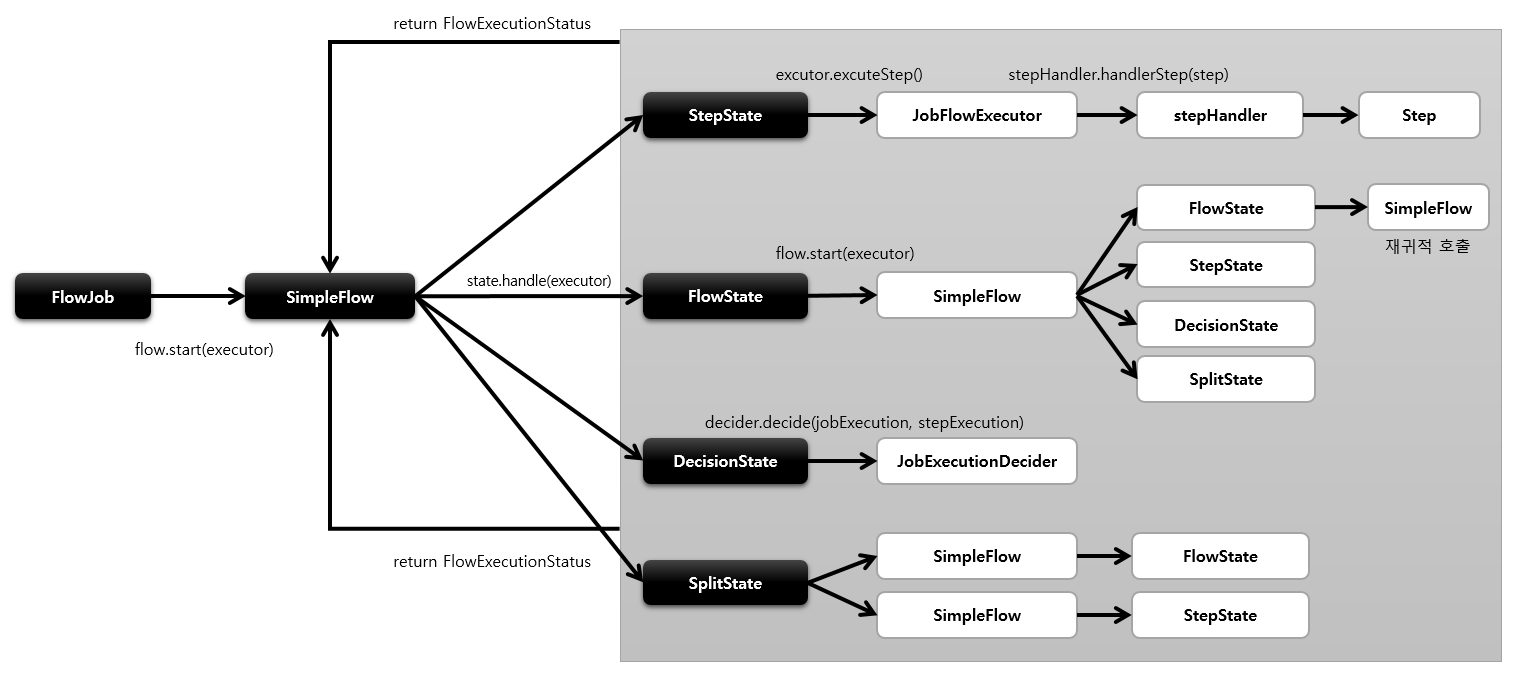
FlowState같은 경우에는 SimpleFlow를 재귀적으로 호출 할 수 있는 구조를 지니고 있다.
SimpleFlow는 handle메소들르 호출해서 상태값만 관심있을뿐 어떤구현체가 호출될 것인지에 대한 관심은 없다.
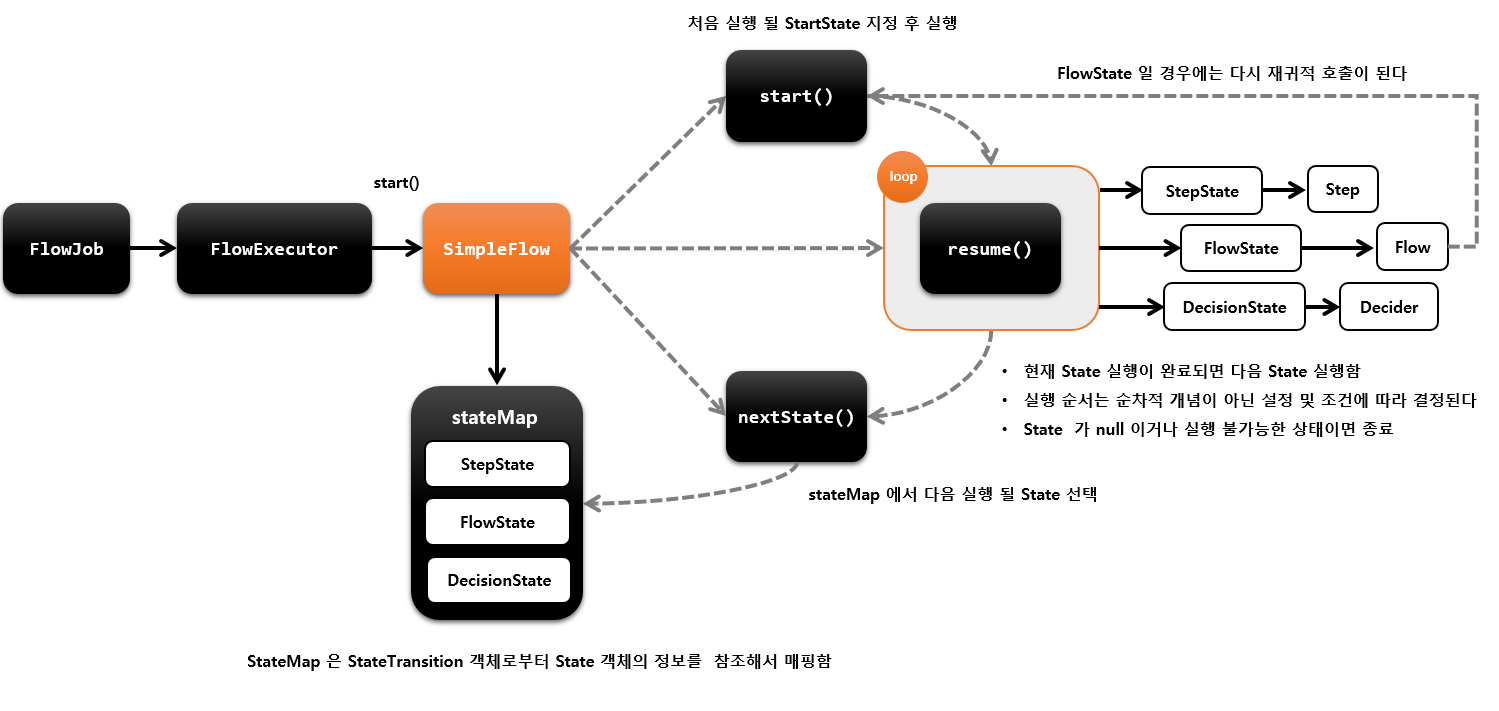
// Terminate if there are no more states
while (isFlowContinued(state, status, stepExecution)) {
stateName = state.getName();
try {
if (logger.isDebugEnabled()) {
logger.debug("Handling state="+stateName);
}
status = state.handle(executor);실행할 state가 더 이상 없을때까지 계속 resume을 호출하며 step, flow ,decider를 수행해 나간다.
protected State nextState(String stateName, FlowExecutionStatus status, StepExecution stepExecution) throws FlowExecutionException {
Set<StateTransition> set = transitionMap.get(stateName);
if (set == null) {
throw new FlowExecutionException(String.format("No transitions found in flow=%s for state=%s", getName(),
stateName));
}
String next = null;
String exitCode = status.getName();
for (StateTransition stateTransition : set) {
if (stateTransition.matches(exitCode) || (exitCode.equals("PENDING") && stateTransition.matches("STOPPED"))) {
if (stateTransition.isEnd()) {
// End of job
return null;
}
next = stateTransition.getNext();
break;
}
}다음 state를 알아보기위해 후보군을 transitionMap에서 꺼내온후에 매칭되는 state를 return 하게 된다.
FlowStep
1. 기본개념
- Step 내에 Flow를 할당하여 실행시키는 도메인 객체
- flowStep 의 BatchStatus와 ExitStatus 는 Flow 의 최종 상태값에 따라 결정된다.
JobStep은 Step에 또다른 job이 있던것이였다. 이 job안에 또 여러개의 step이 존재하게 된다.
FlowStep도 마찬가지이다. Step내에 Flow를 가지고있고 SimpleFlow같은것을 또 다시 실행할 수 있는 구조이다.
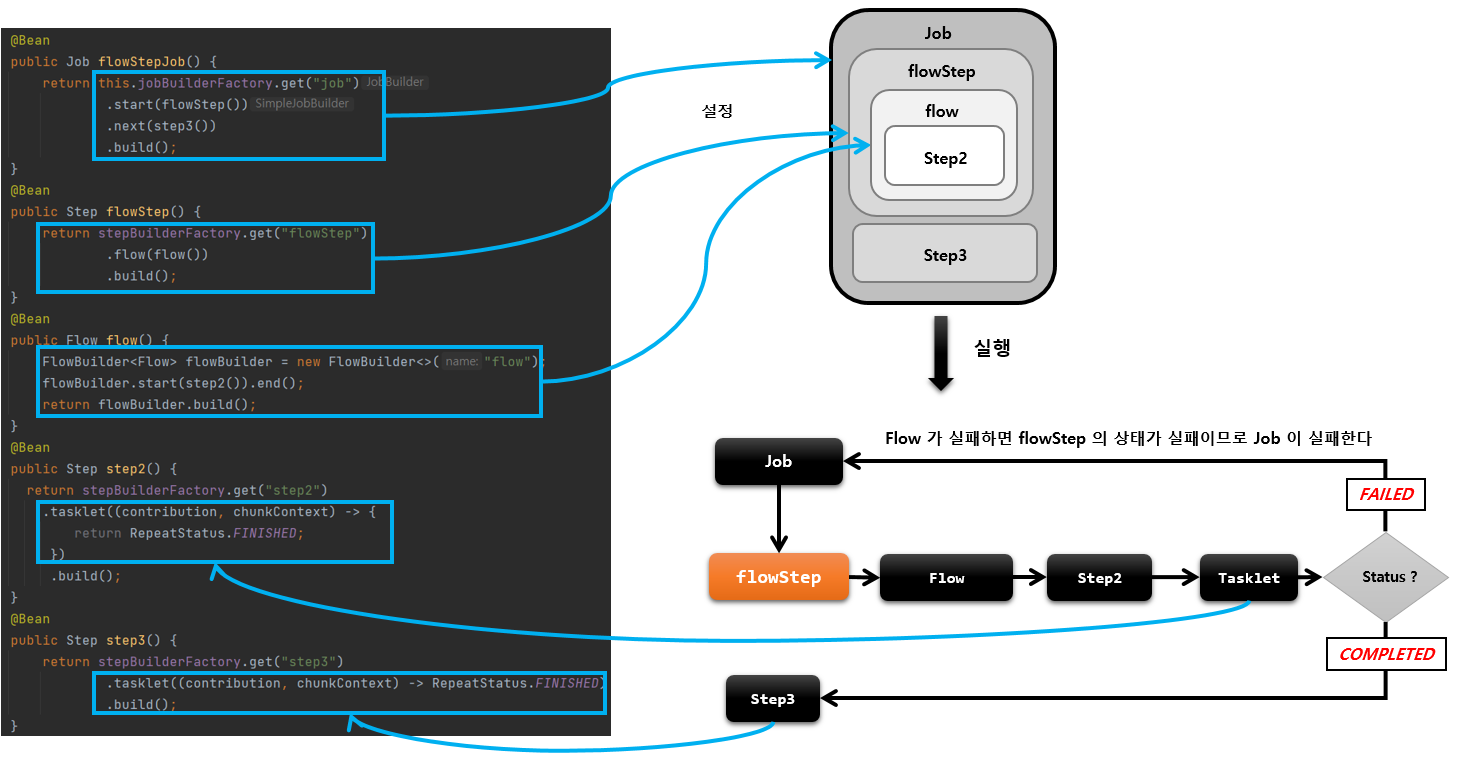
step2에서 실패하면 FlowStep도 결국 step이니까 최종 Job의 flowstep(step2) -> step3 로 진행되지 못했으니 실패하게 된다.
@JobScope , @StepScope
1. Scope
- 스프링 컨테이너에서 빈이 관리되는 범위
- singleton , prototype, request ,session ,application 있으며 기본은 singleton으로 생성됨
2. 스프링 배치 스코프
@JobScope , @StepScope
- Job과 Step의 빈생성과 실행에 관여하는 스코프
- 프록시모드를 기본값으로하는 스코프 - @Scope(value= "job" , proxyMode = ScopedProxyMode.TARGET_CLASS)
- 해당 스코프가 선언되면 Bean의 생성이 앱 구동시점이 아닌 빈의 실행시점에 이루어진다.
- @Values를 주입해서 빈의 실행시점에 값을 참조할 수 있으며 일종의 Lazy Binding 이 가능해진다.
- @Value("#{jobParameters[파라미터명]}"), @Value("#{jobExecutionContext[파라미터명]"}), @Value("#stepExecutionContext[파라미터명]"})
- @Values를 사용할 경우 빈 선언문에 @JobScope , @StepScope를 정의하지않으면 오류를 발생하므로 반드시 선언해줘야함
- 프록시 모드로 빈이 선언되기 때문에 앱 구동시점에는 빈의 프록시 객체가 생성되어 실행 시점에 실제 빈을 호출해준다.
- 병렬처리 시 각 스레드 마다 생성된 스코프 빈이 할당되기 때문에 스레드에 안전하게 실행이 가능하다.
빈이 앱 구동시점이 아닌 빈이 실행되는 시점에 생성이되면 @Values를 동적으로 런타임에 변경하여 적용시킬 수 있다는 의미이다.
3. @JobScope
- step 선언문에 정의한다.
- @Value : jobParameter , jobExecutionContext만 사용가능
4. @StepScope
- Tasklet이나 ItemReader , ItemWriter, ItemProcessor 선언문에 정의한다.
- @Value : jobParameter , jobExecutionContext, stepExecutionContext 사용가능
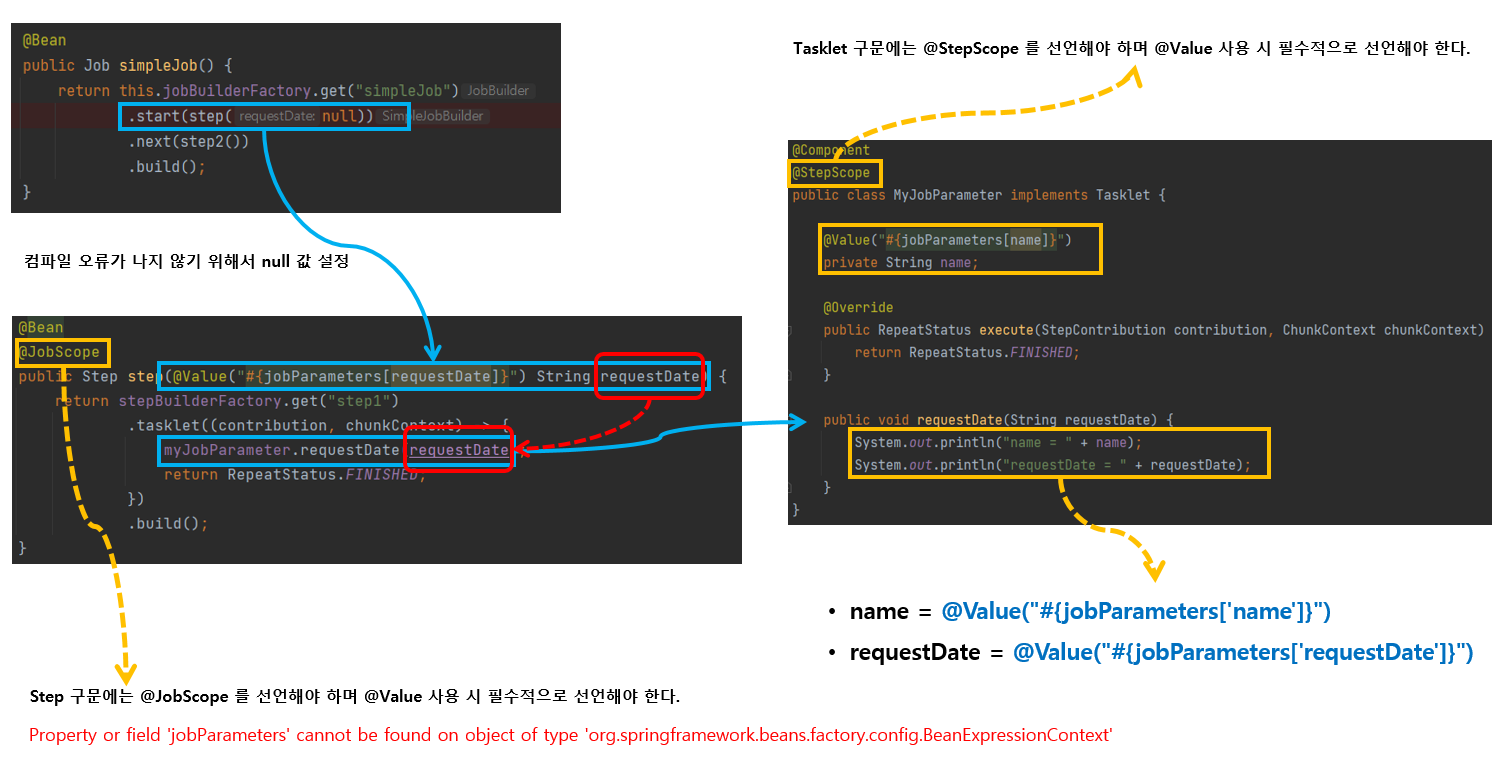
@Bean
@JobScope
public Step step1(@Value("#{jobParameters['message']}") String message) {public class JobListener implements JobExecutionListener {
@Override
public void beforeJob(JobExecution jobExecution) {
jobExecution.getExecutionContext().putString("name", "user1");JobExecution을 Listner를 통해서 주입하는 과정이다. 이를 수행하기위해서는 @JobScope가 필요하고 step1을 호출하는 JobBuilderFactory에서는 null을 인자로 넘겨주어 compile error가 나지 않게 해야한다.
특히 병렬처리 환경에서는 여러 스레드가 실제 빈을 호출하는 시점에 @StepScope 이 선언된 빈의 객체가 스레드마다 생성되어 할당되기 때문에 스레드에 안전한 실행이 가능해진다.
@JobScope , @StepScope 아키텍처
1. Proxy 객체 생성
- @JobScope , @StepScope 어노테이션이 붙은 빈 선언은 내부적으로 빈의 Proxy 객체가 생성된다.
@JobScope
- @Scope(value="job" , proxyMode = ScopedProxyMode.TARGET_CLASS)
@StepScope
- @Scope(value="step" , proxyMode = ScopedProxyMode.TARGET_CLASS)
Job 실행시 Proxy 객체가 실제 빈을 호출해서 해당 메서드를 실행시키는 구조
2. JobScope , StepScope
- Proxy 객체의 실제 대상이 되는 Bean을 등록 , 해제 하는 역할
- 실제 빈을 저장하고 있는 JobContext ,StepContext를 가지고 있다.
3. JobContext , StepContext
- 스프링 컨테이너에서 생성된 빈을 저장하는 컨텍스트 역할
- Job의 실행 시점에서 프록시 객체가 실제 빈을 참조할 때 사용됨
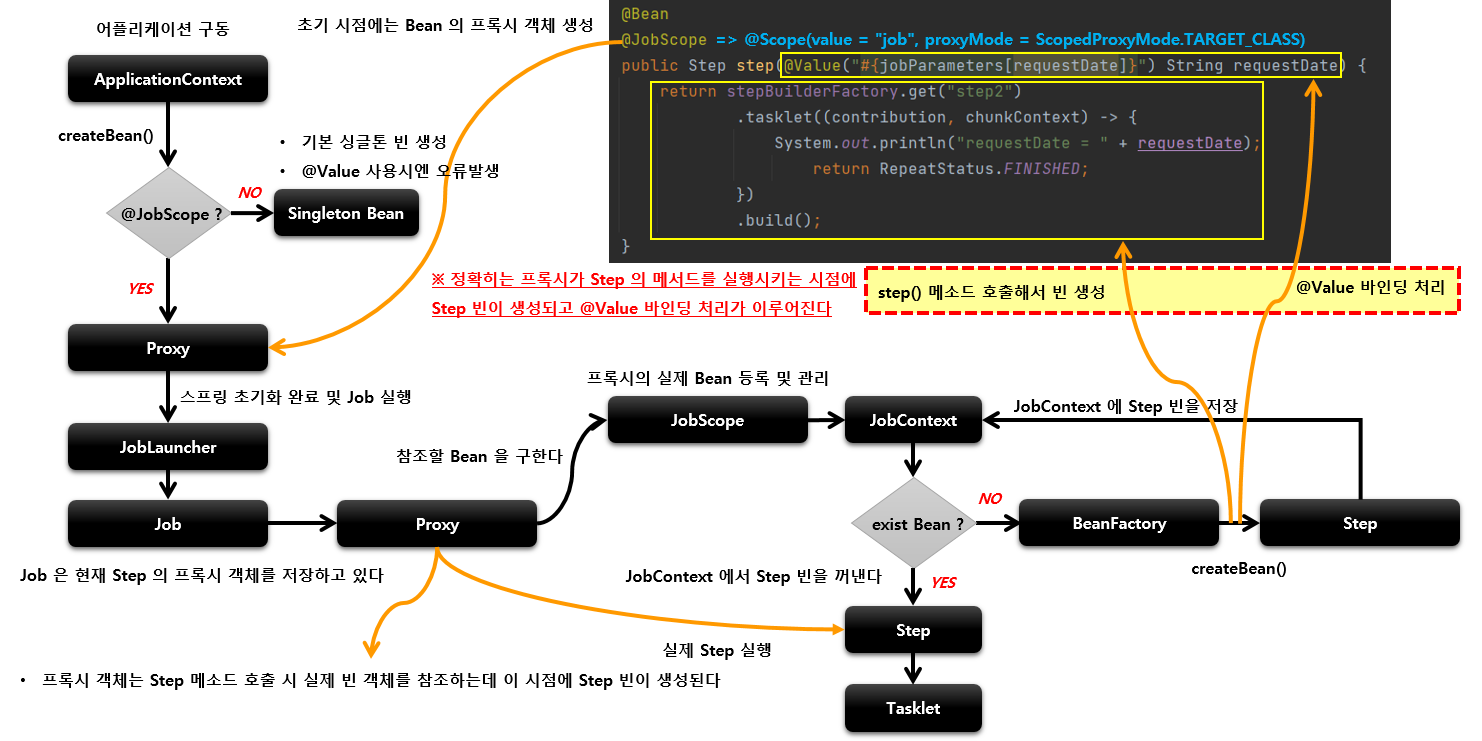
Job은 앱 구동시 Proxy step을 가지고 있다. -> 실제 JobLancher에서 Job을 실행시 실제 step 메소드 호출시에 @Value값을 채워넣은 Bean을 만들어 낸다.
public Object get(String name, ObjectFactory<?> objectFactory) {
JobContext context = getContext();
Object scopedObject = context.getAttribute(name);
if (scopedObject == null) {
synchronized (mutex) {
scopedObject = context.getAttribute(name);
if (scopedObject == null) {
if (logger.isDebugEnabled()) {
logger.debug(String.format("Creating object in scope=%s, name=%s", this.getName(), name));
}
scopedObject = objectFactory.getObject();
context.setAttribute(name, scopedObject);
}
}
}
return scopedObject;
}JobScope#get 메소드에서 objectFactory.getObject를 통해 실제 Step Bean을 호출 시점에 만들어 낸다.
이후 JobContext에 저장하여 프록시가 실제 빈을 호출할때마다 꺼내서 쓰게 해준다.
'WEB > Spring Batch' 카테고리의 다른 글
| 스프링 배치 청크 프로세스 활용 - ItemReader (0) | 2023.03.23 |
|---|---|
| 스프링 배치 청크 프로세스 이해 (2) | 2023.03.22 |
| 스프링 배치 실행 - Step (0) | 2023.02.28 |
| 스프링 배치 실행 - Job (0) | 2023.02.23 |
| 스프링 배치 도메인 이해 (0) | 2023.02.17 |