경로 표현식 용어 정리
상태필드 = 단순히 값을 저장하기위한 필드 예) m.username
경로탐색의 끝, 더 이상 탐색하지않는다.
명시적 조인 = join 키워드 직접사용
select m from Member m join m.team t묵시적 조인 = 경로 표현식에 의해 묵시적으로 SQL 조인 발생 (내부 조인만 가능)
select m.team from Member m
연관 필드 = 연관관계를 위한필드
단일 값 연관 필드
@ManyToOne , @OneToOne 대상이 엔티티다 예) m.team
String query = "select m.team From Member m";
List<Team> resultList = em.createQuery(query, Team.class)
.getResultList();Hibernate:
/* select
m.team
From
Member m */ select
team1_.id as id1_3_,
team1_.name as name2_3_
from
Member member0_
inner join
Team team1_
on member0_.TEAM_ID=team1_.id묵시적 내부조인(inner join) 발생, 탐색이 더 가능하다
컬렉션 값 연관 필드
@OneToMany, @ManyToMany, 대상이 컬렉션 예) m.orders , t.members 에서는 size 만 가능하다. 더 이상 객체 그래프를 탐색을 할 수 없다. -> 명시적 조인을 통해 별칭을 얻으면 가능하다.
m.username의 경우 상태필드에 도달했기에 더이상 경로탐색이 당연하게 불가능하다.
select t.members.(username 안됨) From Team t;
select m.username From Team t join t.members m; // 명시적 조인을 통해 별칭을 얻으면 가능
select o.member.team from Order o; // 묵시적 조인
select t from Order o
join o.member m
join m.team t // 명시적 조인항상 뭘 하든 명시적 조인을 써야 한다!!! 묵시적 조인은 위험한 존재이다.
JPQL fetch join - 1
JPQL에서 성능 최적화를 위해 제공하는 기능
회원을 조회하면서 연관된 팀도 함께 조회하고 싶다
JPQL
select m from Member m join fetch m.teamSQL
select M.* , T.* from Member M
inner join Team T on M.team_id = T.idsql 을 보면 회원 뿐만 아니라 팀 T.* 함께 select 된다. 즉시로딩이라 같은 것이다.

String query = "select m From Member m";
List<Member> resultList = em.createQuery(query, Member.class)
.getResultList();
for (Member member : resultList)
{
System.out.println("member.getUsername() = " + member.getUsername() + ", " + member.getTeam().getName());
}Hibernate:
/* select
m
From
Member m */ select
member0_.id as id1_0_,
member0_.age as age2_0_,
member0_.TEAM_ID as team_id4_0_,
member0_.username as username3_0_
from
Member member0_
Hibernate:
select
team0_.id as id1_3_0_,
team0_.name as name2_3_0_
from
Team team0_
where
team0_.id=?
member.getUsername() = member1, TeamA
member.getUsername() = member2, TeamA
Hibernate:
select
team0_.id as id1_3_0_,
team0_.name as name2_3_0_
from
Team team0_
where
team0_.id=?
member.getUsername() = member3, TeamB
쿼리가 첫 for 문에서 getTeam().getName()을 실행할때 team을 select 해온다 지연로딩이기 때문이다. lazy이기에 현재는 team 에 프록시 객체가 들어가 있기 때문이다.
그 다음에 2번쨰 for문에서 첫번째 for문에서 회원1을 불러올떄 TeamA를 1차 캐시(영속성 context)에 저장을 해두었기 때문에 그냥 1차 캐시에서 가져온다.
마지막에는 회원 3은 TeamB 이기 때문에 다시 쿼리를 날려서 가져온다.
이런 현상을 1+N 즉 Member의 Team을 알아보기 위해 날린 1개의 쿼리 때문에 추가적으로 N 개의 쿼리가 호출 되는것이다.
미리 fetch join을 써서 한번에 가져와 이런일을 방지하는것이 좋다. 또한 지연로딩을 선택했더라도 fetch join이 항상 우선순위를 가진다.
컬렉션 패치 조인 = 일대다 관계, 컬렉션 패치 조인
JPQL
select t
from Team t join fetch t.members
where t.name = "팀A"SQL
select T.* , M.*
from Team T
inner join member M on T.id = M.team_id
where T.name = "팀A" String query = "select t From Team t join fetch t.members";
List<Team> resultList = em.createQuery(query, Team.class)
.getResultList();
for (Team team : resultList)
{
System.out.println("team = " + team.getName() + "|members=" + team.getMembers().size());
for (Member member : team.getMembers())
{
System.out.println("-> member = " + member);
}
}Hibernate:
/* select
t
From
Team t
join
fetch t.members */ select
team0_.id as id1_3_0_,
members1_.id as id1_0_1_,
team0_.name as name2_3_0_,
members1_.age as age2_0_1_,
members1_.TEAM_ID as team_id4_0_1_,
members1_.username as username3_0_1_,
members1_.TEAM_ID as team_id4_0_0__,
members1_.id as id1_0_0__
from
Team team0_
inner join
Member members1_
on team0_.id=members1_.TEAM_ID
team = TeamA|members=2
-> member = jpql.Member@55651434
-> member = jpql.Member@60a19573
team = TeamA|members=2
-> member = jpql.Member@55651434
-> member = jpql.Member@60a19573
team = TeamB|members=1
-> member = jpql.Member@134ff8f8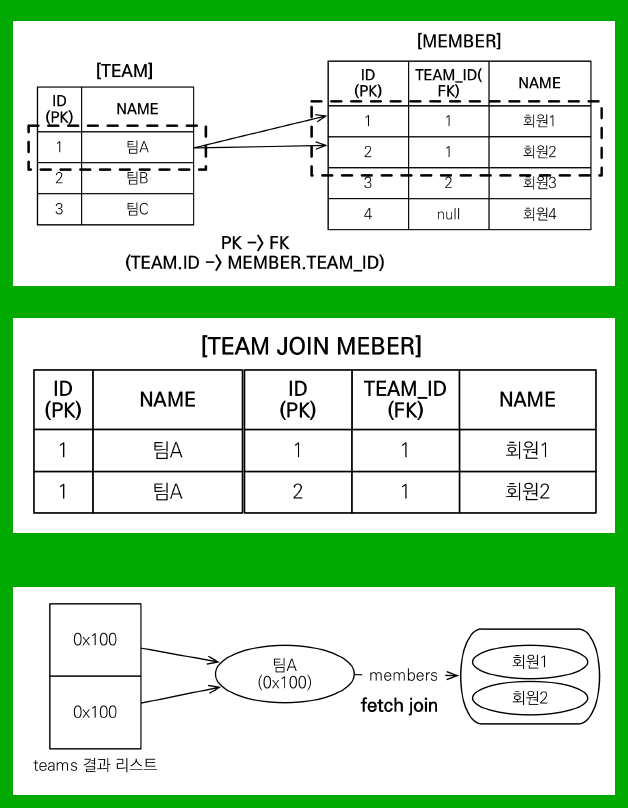
위에 저런식으로 팀A에 있는 Member가 2명이기 때문에 row가 하나 더 생겨서 총 3개의 Team이 있는것처럼 불러오는 것이다.
이런 중복을 제거하기 위해서는 sql 의 distinct로는 불가능하다. row 자체가 완전히 똑같아야지만 중복으로 인식하기 때문이다.
JPA 의 distinct 는 추가로 애플리케이션에서 중복을 제거 해준다. 같은 식별자를 가진 Team 엔티티는 제거해준다.
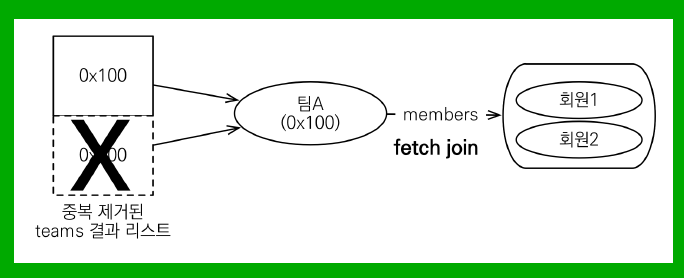
String query = "select distinct t From Team t join fetch t.members";team = TeamA|members=2
-> member = jpql.Member@3c91530d
-> member = jpql.Member@1115433e
team = TeamB|members=1
-> member = jpql.Member@513b52af중복이 제거된것을 확인 할 수 있다.
패치 초인과 일반 조인의 차이
일반 조인 실행시 연관된 엔티티를 함께 조회하지 않는다.
JPQL(그냥조인)은 결과를 반환할 때 연관관계를 고려하지않고 select 절에 지정한 엔티티만 조회 한다.
패치조인은 사용할 때만 연관된 엔티티도 함께 조회(즉시 로딩) , 객체 그래프를 SQL한번에 조회하는 개념
즉시로딩과 fetch 조인의 차이
https://www.inflearn.com/questions/39516
em.find 일시에는 fetch join 마냥 동작을 한다. 하지만 jpql 은 이야기가 다르다.
즉시로딩으로 설정이 되어있어도 select m from member m 을 하게되면
jpql 은 eager와 무관하게 sql 로 그대로 번역 -> select m.* from member
member만 조회하고 team은 조회하지 않음 -> 나중에 jpa 가 eager임을 발견하고 추가적으로 team 을 가져오는 쿼리를 날림 -> N+1 문제 발생
패치 조인의 특징과 한계
패치 초인 대상에는 별칭을 줄 수 없다. (하이버네이트는 가능 하지만 사용지양)
둘 이상의 컬렉션은 패치 조인 할 수 없다.
컬렉션을 패치 조인하면 페이징 API(setFirstResult , setMaxResults) 를 사용할 수 없다. 데이터 뻥튀기때문.
- 일대일 , 다대일 같은 단일 값 연관 필드들은 패치 조인해도 페이징 가능
- 하이버네이트는 경고 로그를 남기고 메모리에서 페이징(매우위험)
방향을 뒤집어서 데이터 뻥튀기가 안일어나게 해서 페이징하면 문제가 없다.
@BatchSize(size = 100)
@OneToMany(mappedBy = "team")
private List<Member> members = new ArrayList<>(); String query = "select t From Team t";
List<Team> resultList = em.createQuery(query, Team.class)
.setFirstResult(0)
.setMaxResults(2)
.getResultList();
for (Team team : resultList)
{
System.out.println("team = " + team.getName() + "|members=" + team.getMembers().size());
for (Member member : team.getMembers())
{
System.out.println("-> member = " + member);
}
}Hibernate:
/* load one-to-many jpql.Team.members */ select
members0_.TEAM_ID as team_id4_0_1_,
members0_.id as id1_0_1_,
members0_.id as id1_0_0_,
members0_.age as age2_0_0_,
members0_.TEAM_ID as team_id4_0_0_,
members0_.username as username3_0_0_
from
Member members0_
where
members0_.TEAM_ID in (
?, ?
)
team = TeamA|members=2
-> member = jpql.Member@47ac613b
-> member = jpql.Member@6bccd036
team = TeamB|members=1
-> member = jpql.Member@4f4c88f9
@Batchsize(size=100) 를 통하여 페이징을 해결할 수 있다.
글로벌 세팅도 가능하다. hibernate.default_batch_size value = "100" .
150개의 팀이 존재한다고 했을때 1~100 팀에 해당되는 member.Team_id in ( 1~100) 이라는 쿼리를 날려서 연관된 엔티티모두를 select해서 받아온다. 그리고 나머지 member.Team_id in (101~150) 이라는 쿼리를 날려서 받아온다.
엔티티 직접 사용 - 기본 키 값
JPQL에서 엔티티를 직접 사용하면 SQL에서 해당 엔티티의 기본 키 값을 사용
JPQL
select count(m.id) from Member m // 엔티티의 PK를 사용
select count(m) from Member m // 엔티티를 직접사용SQL
select count(m.id) as cnt from Member m
@NamedQuery
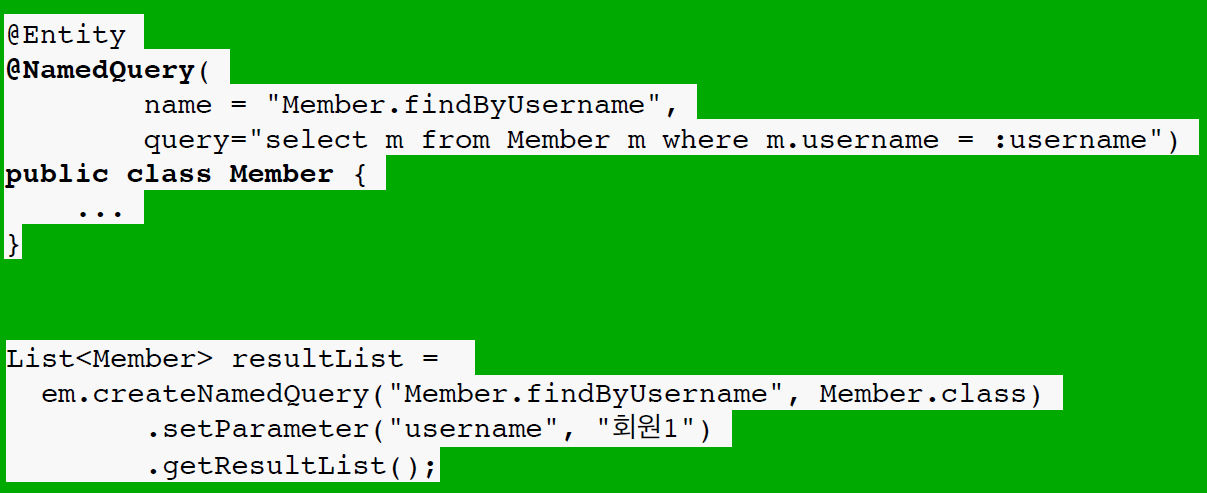
위와 같이 그냥 쿼리를 함수처럼 재사용하게 해주는 기능이다.
jpa 가 미리 jpql 로 작성된것을 파싱하고 캐싱하고있어서 productive 하다.
애플리케이션 로딩 시점에서 쿼리를 검증가능 = 실행하는 시점에 String인데 불구하고 오타 및 오류를 잡아준다. 나중에 Spring Data JPA를 배우면 이것을 한번 더 맛 볼 것이다.
벌크 연산
쿼리 한 번으로 여러 테이블 로우 변경(엔티티)
executeUpdate()의 결과는 영향 받은 엔티티 수 반환
Update, Delete 지원
벌크연산 주의
벌크연산은 영속성 컨텍스트를 무시하고 데이터베이스에 직접 쿼리한다. 2가지 방법이 존재한다.
1. 벌크 연산을 먼저 실행
2. 벌크 연산 후 영속성 컨텍스트 초기화
em.clear를 안하는 경우에 영속성 컨텍스트가 옛날것이 그대로 남아 있어서 데이터 정합성 문제가 생긴다.
'WEB > JPA' 카테고리의 다른 글
| 실전! 스프링부트와 JPA와 활용2 (컬렉션 조회 최적화) (0) | 2021.04.06 |
|---|---|
| 실전! 스프링 부트와 JPA 활용2 (API 개발기본 , 지연로딩과 조회 성능 최적화) (0) | 2021.04.03 |
| 김영한 (ORM 표준 JPA 프로그래밍 10) 객체지향 쿼리 언어 소개 (0) | 2021.03.18 |
| 김영한 (ORM 표준 JPA 프로그래밍 9) 값 타입 (0) | 2021.03.16 |
| 김영한 (ORM 표준 JPA 프로그래밍 8) 프록시와 연관관계 관리 (0) | 2021.03.14 |