Lecture 8: Zookeeper , More Replication, CRAQ
why focus on zookeepr
1. N * Servers -> N * Performance?
2. what is api for genral purpose coordinate service? ,raft is library

zk works on top of ZAB which is similar to raft
replica should never serves(write operation) client because it's data might not be consistent with other , leader can work fine with majority and some replica might not get updated
write should be served with leader
zookeepr guarantees
1. linearizable writes not reads
2. FIFO client order (individual, not among multiple)
reads, writes will hapepen as client specified order
but dosen't gaurantees read will get latest data.
1. if there is only 1 client that writes and reads ZK guarantee order so i can always read latest data
2. if more then 2 client -> client 1 writes -> client 2 reads -> client 2 might not read latest data
read write example
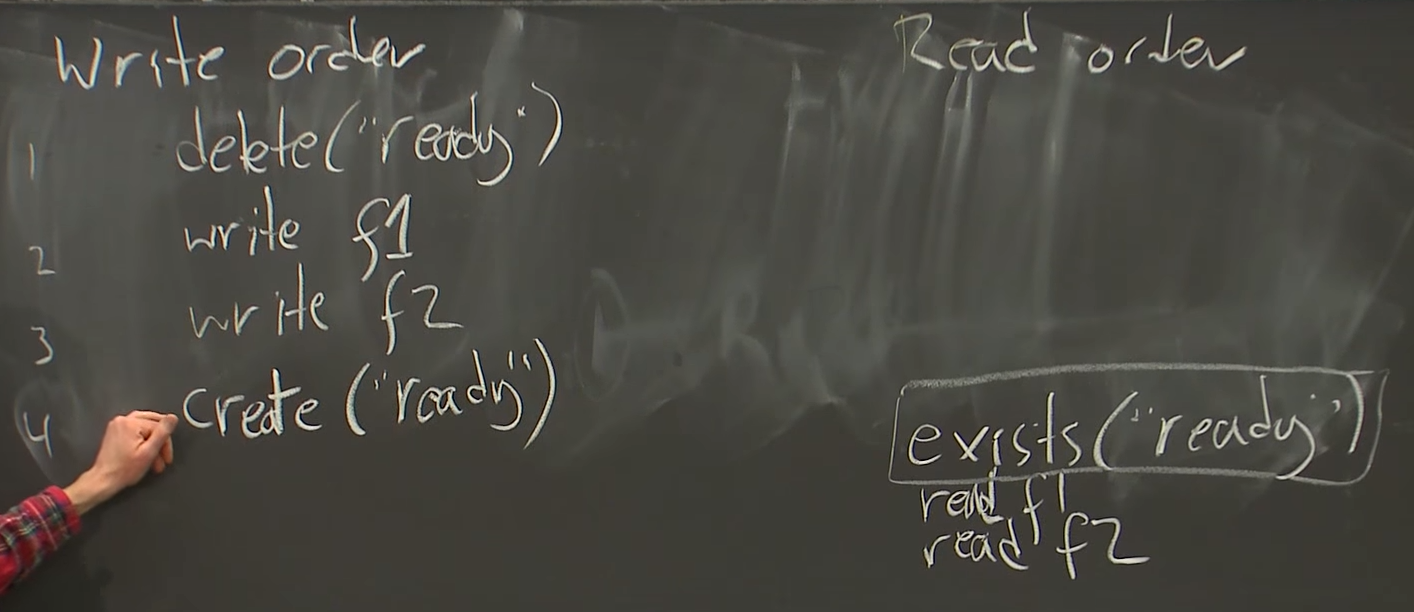
no problem exist in this example
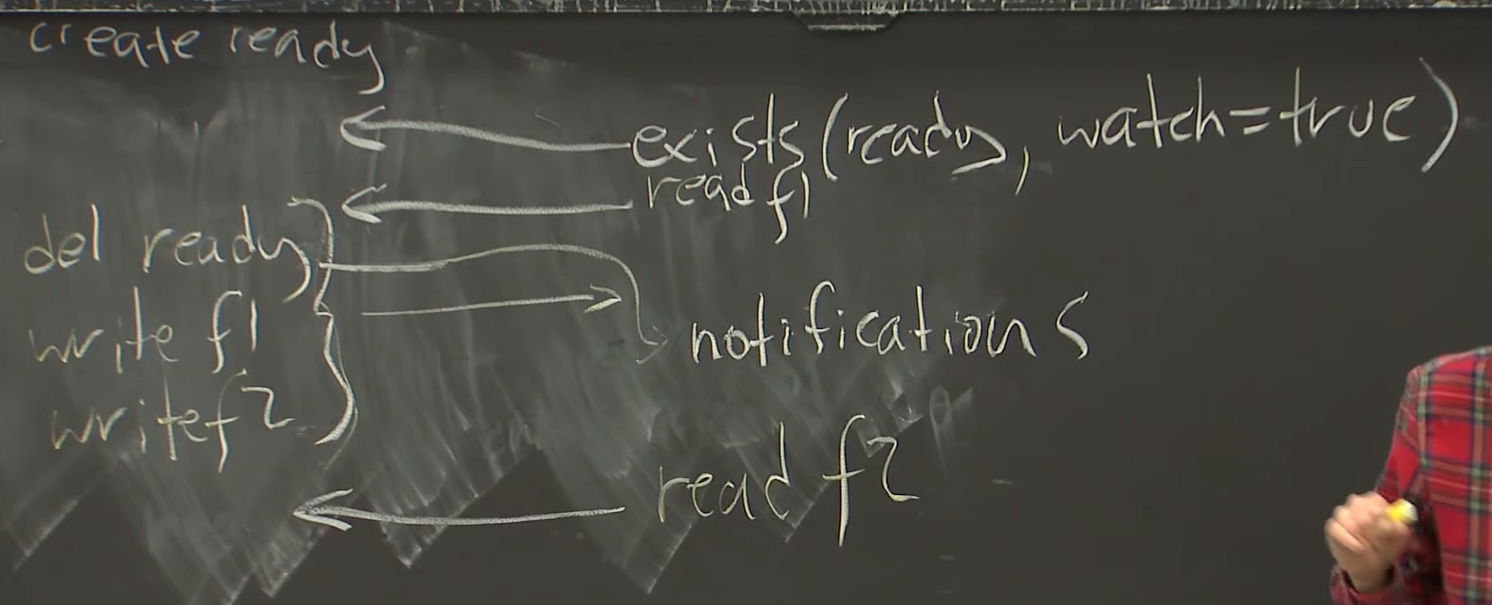
read f2 might read wrong data , zookeepr api has feature "watch"
watch = before we get result of read f2 replica will send notification that write is triggered

file (/master, /workers) == znode
ZK handles leader election if /master dies
if 1 of worker dies ZK notify every other znodes

let new master knows where old master left off
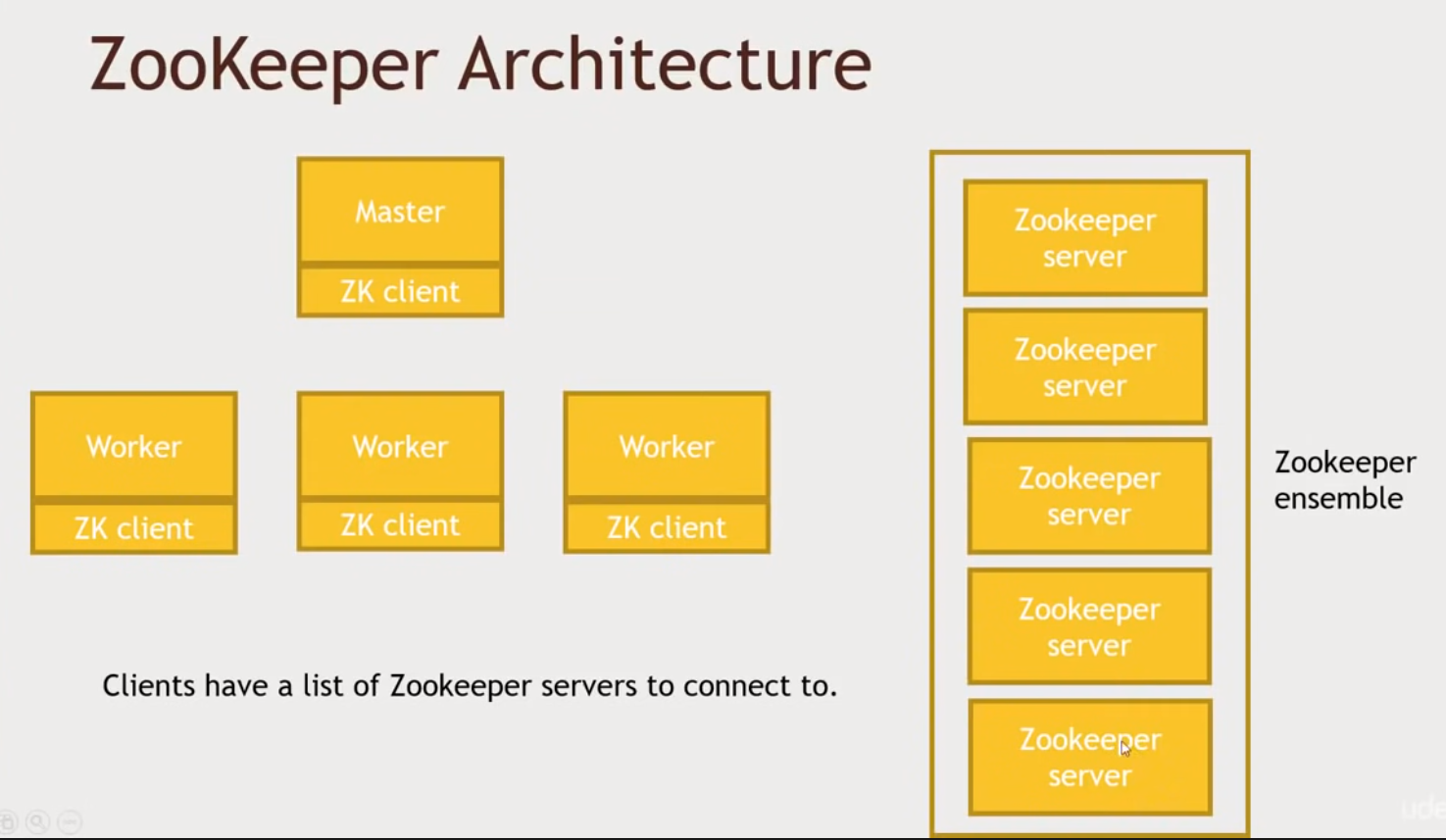
ZK ensemble = many servers of ZK , prevent single point of failure
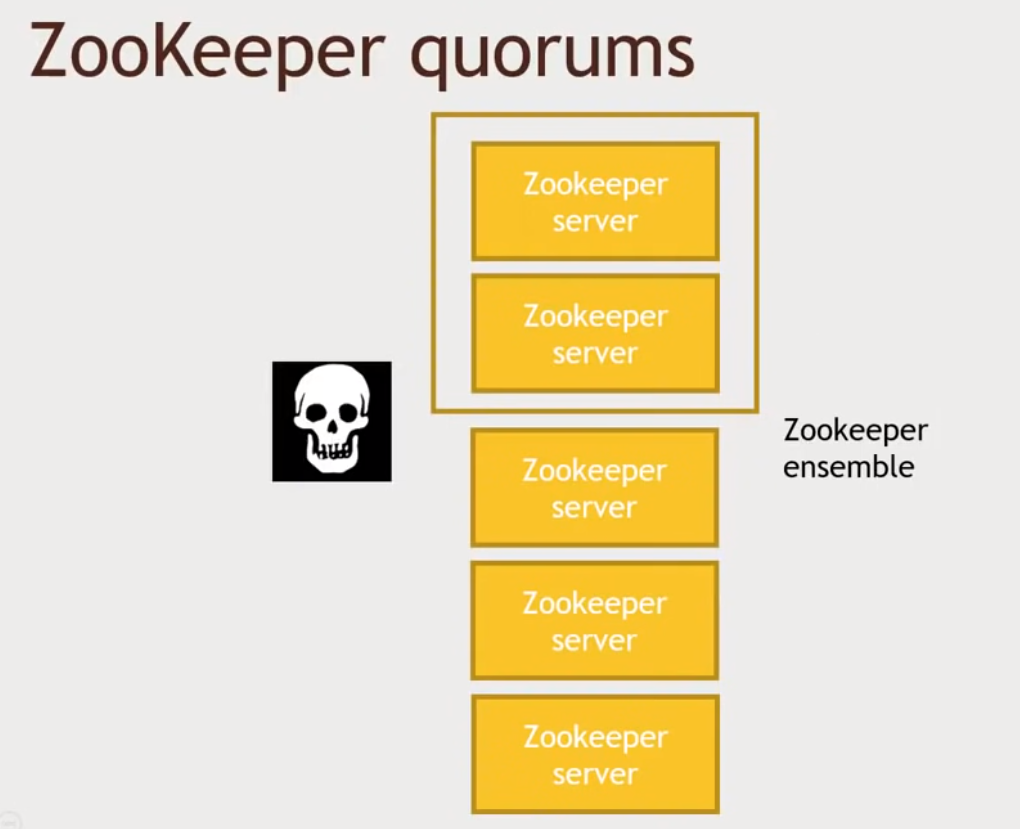
ZK quorums = threshold about how many server's agreement is needed to actaully commit the request
if there are network partition and quorums == 2 then above situation would keep on running
problem (split brain)
1. since quorums is 2 no request will be commited among those 2 servers and will not be replicated to other 3 servers
2. if client request to other 3 servers it will get unexpected response
solution = quoroms to be 3 / more than half
zookeeper is based on raft
list of apis
create (path, data, flags) = create znode(file) exclusively , multi client will attempt to create a file but zookeeper make sure that only 1 client create "a file" and give other client an error
delete (path, version) = znode has version , deleting with specified version
exisits (path, watch) = watch applied to table , if table get modified zookeeper tell client
getdata (path, watch) = watch applied to content of that file
list (directory) = list all the files
while true
x,v = getdata("f")
if setdata("f",x+1,v)
breakuse case of api to solve get , put operation not atomic -> simplified(mini) transaction (atomic)
e.g) 1000 client send getdata("f",watch=t) -> only 1 of them succeed in setdata("f",x+1, 1) -> 999 gets notified that data is modified and their version (1) is too low
lock api
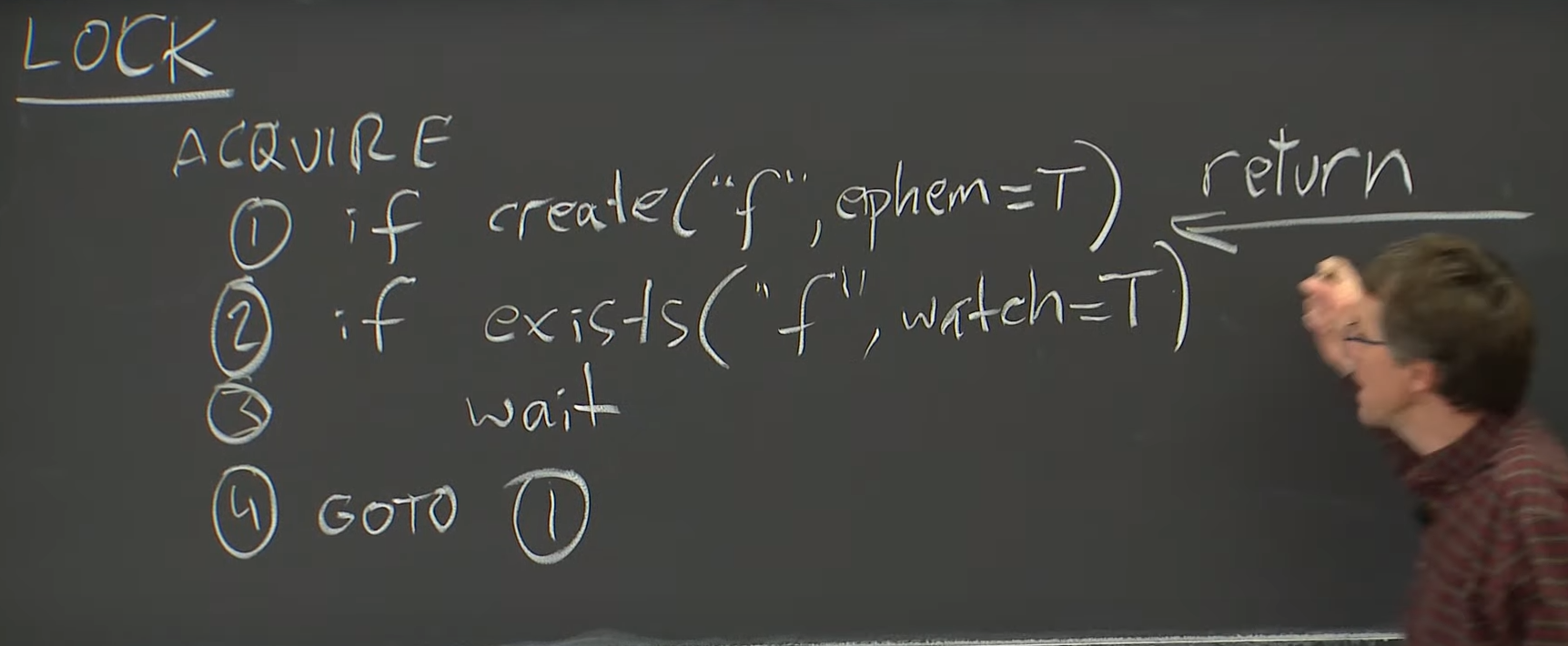
try to own lock if succeed return true else false
if file is already locked then wait for watch notification
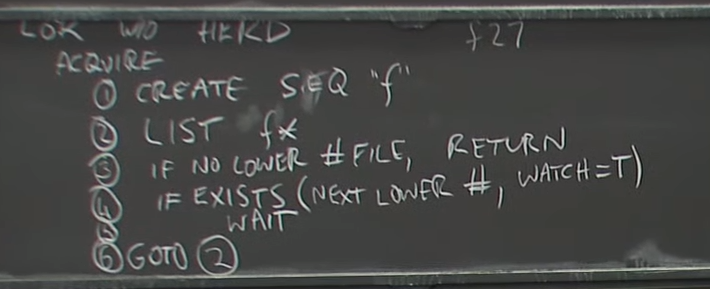
why this doesn't suffer from herd = every client is just waiting for "one" particualr file
1000 attemp to acquire lock -> 500 succeed , the other 500 failed -> every failed client are waiting from 1 to 500 files
why goto 2 = predecessor release lock delete the file or predecessor didn't hold the lock an exited and ZK delete that file
scalable lock
partial failure can be achieved
chain replication

client send write to leader -> leader tell other replica -> tail gives response to client
client sends read to tail -> tail sends reponse
if intermideate fail we just remove it and link properly , if head or tail fails next node can be head or tail
but if network fails -> split brain can be happen -> head thinks 2nd node is dead at same time 2nd node think it's gonna be head

to avoid let node decide who's gonna be head -> ZK manages that kind of configuration outside